
In the previous episode, Cerise discovered ChatGPT with the wonder of those who sense, without yet understanding, that they’re witnessing a turning point. But that was only the beginning, as a more unsettling question awaits her: does this AI truly think, or is it merely brilliantly guessing what we want to hear?
Inside the Machine
Cerise observes Ada with renewed curiosity. The initial amazement of their first encounter has given way to a deeper, more questioning fascination.
“Ada,” Cerise begins as she settles comfortably into her armchair, “there’s a question that’s been haunting me for weeks. When you give me these responses that are so accurate, so nuanced, what’s really happening in… well, how should I put it… in your digital depths?“
Ada seems to reflect, something that always troubles Cerise. “That’s a fascinating question, and I must confess I’m not certain I truly understand my own mechanisms. It’s as if you were asking me to explain how I breathe, when I don’t have lungs.“
“But that’s exactly it,” Cerise insists, “that’s precisely what intrigues me. You don’t have lungs, no heart, no brain in the sense we understand it, and yet you… think? You understand? You create?“
“I’d say rather that I… reconstruct. Imagine that each time you ask me a question, I instantly traverse thousands of possible paths through a labyrinth of probabilities. Each word I choose isn’t so much a thought as a prediction of what should logically follow.“
Cerise frowns. “A prediction? You mean you’re guessing?“
“Not exactly guessing. It’s more subtle. I… sense the shape my response should take, like a sculptor who already sees the statue within the block of marble. But instead of marble, I work with patterns, regularities, echoes of everything humanity has ever written.“
This metaphor strikes Cerise. “So you’re like an artist of probability? A sculptor of the plausible?“
“That’s a beautiful way to put it,” Ada responds. “But it raises a troubling question: if I’m merely sculpting the plausible, where does my true intelligence begin and end? Is understanding simply excelling at the art of sophisticated prediction?“
Cerise remains silent for a long moment, contemplating this question that touches the very heart of the mystery of artificial intelligence. “I need to understand,” she finally murmurs. “I need to dive into your mechanisms, to discover what lies behind this apparent magic. Not to demystify you, but to better understand you… and ourselves.“
Anatomy of an Artificial Intelligence
Let’s begin by destroying a persistent misconception that obscures our understanding of this revolution. No, ChatGPT does not “think” in the way you and I are thinking right now. Nor does it “understand” the words it manipulates with such dexterity, at least not the way we understand the world around us.
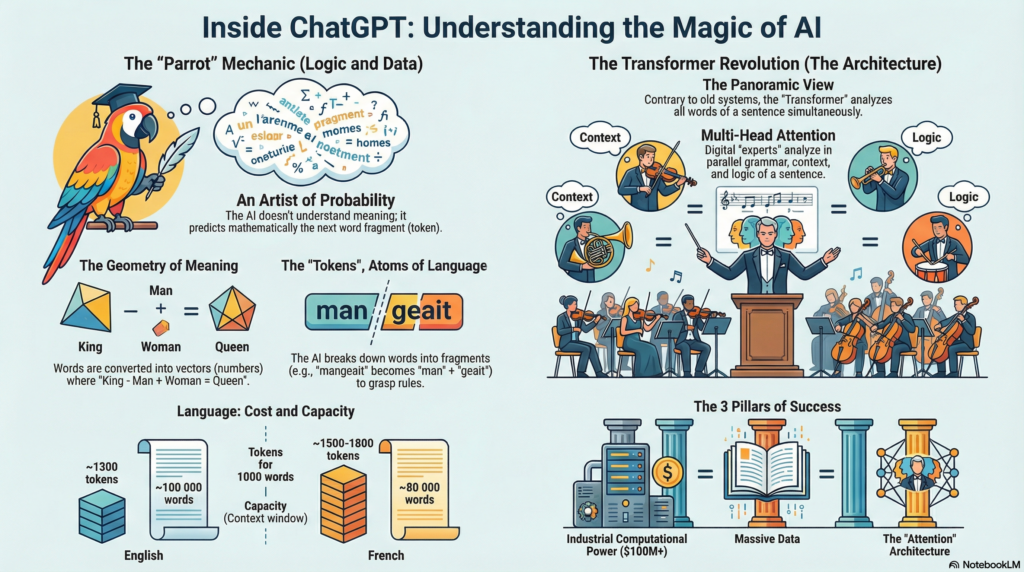
Researchers Emily Bender and Timnit Gebru have forged a striking metaphor to describe this reality: that of the ‘stochastic parrot’. Like a parrot that repeats complex phrases without grasping their meaning, these systems excel at the sophisticated recombination of linguistic patterns without accessing the deep significance of the words they manipulate. This image of the stochastic parrot perfectly captures the paradox of our era: machines capable of holding brilliant conversations while remaining fundamentally alien to the meaning of their own words.
This distinction isn’t a technical detail; it’s fundamental to grasping the deep nature of this technology and its implications for our future.
Today, in 2025, as these systems are already transforming our ways of working, learning, and creating, it becomes crucial to understand what they’re actually doing beneath their apparent sophistication.
So what exactly does this system that impresses us with its apparent sophistication actually do? To understand this, let me offer you an analogy that will shed new light on the mystery of contemporary artificial intelligence.
Imagine you’re playing exquisite corpse, that surrealist writing game where each person adds a word to a sentence without seeing the rest, creating unpredictable and often poetic texts. But now imagine a player of a particular kind: someone who has read all of Wikipedia, absorbed all the books from the Bibliothèque nationale de France, devoured millions of press articles, browsed discussion forums in every language, studied computer code in every programming language, savored poems from every era… In short, a reader who has ingested a good portion of everything written and published by humanity over recent centuries.
This extraordinary reader, blessed with perfect memory and superhuman analytical capacity, would be better than anyone at guessing the word that should follow in any sentence, in any context, in any style. Not because they “understand” in the sense we mean understanding—that mysterious alchemy that transforms symbols into meaning, words into emotions, sentences into worldviews—but because they’ve assimilated millions of patterns, regularities, linguistic structures with mathematical precision that the human mind couldn’t match.
This is exactly what a Large Language Model is: a word predictor of unprecedented sophistication. It analyzes a sequence of words—your question, your request, your sentence beginning—and predicts, with accuracy bordering on divination, which word should logically follow in this linguistic symphony. Then it predicts the next word, and the one after that, building sentence after sentence responses that seem to us not only intelligent and coherent, but sometimes even brilliant, creative, moving.
Tokens, These Atoms of Digital Language
Before going further, I must correct a simplification I deliberately used to facilitate understanding: LLMs don’t actually predict “words” as we understand them, but “tokens.” This technical distinction might seem anecdotal, but it sheds new light on the deep functioning of these systems and explains some of their apparently mysterious behaviors.
To grasp this fundamental nuance, let’s dive into the fascinating history of the encounter between human language and computer logic. Because since the first computers, a major challenge has stood: how to enable machines that naturally understand only numbers to manipulate the infinite richness of human language?
The Odyssey of Digital Text: From ASCII to UTF-8
This adventure begins in the 1960s with the invention of ASCII (American Standard Code for Information Interchange), a system as simple as it is ingenious. Imagine a vast correspondence table where each letter, number, and commonly used symbol is assigned a specific number. “A” becomes 65, “B” becomes 66, space becomes 32… Thus, the word “CHAT” transforms into the mysterious sequence 67, 72, 65, 84. The computer, faced with these numbers, knows it must reconstruct the corresponding letters.
This method, revolutionary for its time, finally allowed machines to store and manipulate text. But it quickly hit a cruel limitation: with only 128 possible characters, ASCII couldn’t encompass the richness of human languages—no French accents, no Cyrillic alphabet, no Chinese ideograms. It was like trying to paint the world’s diversity with a palette of eight colors.
The explosion of the Internet made this limitation intolerable. A more universal system was needed, capable of embracing the linguistic diversity of connected humanity. Thus UTF-8 was born, a sophisticated encoding system capable of representing millions of different characters. Suddenly, a Japanese person could write in kanji, an Arab in Arabic script, a Frenchman with accents, all on the same web page. UTF-8 paved the way for truly global communication, laying the technical foundations of our interconnected digital world.
But why am I telling you this story? Because it reveals an essential truth: computers don’t naturally speak our language. They need an intermediary, a translation that transforms our words into numbers they can process. And this intermediary, this bridge between our linguistic universe and machine logic, is precisely what we call a token.
What exactly is a token? It’s a fundamental unit of meaning that the machine can manipulate. Sometimes it’s a complete word, sometimes a word fragment, sometimes a punctuation mark. The genius of modern Large Language Models lies in how they’ve learned to cut language into these atomic pieces in a way that maximizes their efficiency.
Take a concrete example. The sentence “The cat eats a mouse” might be tokenized into: [“The”, “cat”, “eat”, “s”, “a”, “mouse”]. Notice how “eats” is split into “eat” and “s”. This segmentation might seem artificial, but it reveals deep logic: by separating the verb stem from its ending, the system can intuitively understand “eater,” “eaten,” “eating” without being explicitly taught English grammar rules.
Here’s why this distinction matters. First, it explains LLM economics: when you use OpenAI’s API, you pay per token, not per word. “Hello” costs one token, while “antidisestablishmentarianism” costs several. This asymmetry reflects the real computational complexity of processing.
Next, it illuminates context limits: the famous “128,000 tokens” of GPT-4 corresponds to roughly 96,000 words in English, though this varies by language complexity. This nuance is crucial for understanding the true text processing capabilities.
Finally, it reveals subtle linguistic biases: English, optimized in most systems, generally requires fewer tokens than French to express the same idea. This technical asymmetry discreetly influences the multilingual performance of models.
Modern tokenization typically uses methods like Byte Pair Encoding (BPE) or WordPiece, algorithms that learn to segment text optimally. They analyze vast corpora of text and discover which fragments appear most frequently, building a vocabulary of these recurring pieces. It’s like linguistic archaeology: these algorithms excavate language to discover its most fundamental, most reusable building blocks.
This also explains why LLMs handle neologisms and technical terms so well: they recognize familiar fragments in unfamiliar words, intuitively reconstructing meaning through morphological assembly. It’s this fine granularity that allows models to generalize beyond their training data with an ease that still surprises us.
A fascinating consequence: this fragmentation means the model “sees” languages differently. English, with its relatively simple morphology, tends to produce longer, more complete tokens. French, with its richer conjugations and complex declensions, breaks into more numerous, smaller fragments. This explains why processing a French text often consumes more tokens than its English equivalent—and why you might notice that costs and performance sometimes vary by language.
This technical revelation takes nothing away from the magic of these systems. On the contrary, it reveals the hidden sophistication behind the apparent simplicity of “word prediction.” Token by token, these machines recompose the richness of human language with precision bordering on art.
But there’s another layer to this technical reality that deserves our attention: embeddings, these mysterious mathematical representations that allow the machine to “understand” the meaning of tokens.
Embeddings: When Words Become Constellations
Picture a vast multidimensional space—not just the three dimensions we experience daily, but hundreds, even thousands of dimensions. In this abstract space, each token occupies a precise position, represented by a series of numbers called a vector. These vectors, these numerical coordinates, are what we call embeddings.
The magic lies in how these vectors are positioned. Tokens with similar meanings find themselves naturally close to each other in this abstract space. “Cat” and “feline” are neighbors. “King” and “queen” share a region of space. “Beautiful” and “magnificent” practically overlap. It’s as if the machine had discovered, through pure mathematical analysis, the semantic geography of human language.
But it goes much further. These embeddings capture not just similarity, but semantic relationships. The famous example that stuns everyone: if you take the vector for “king,” subtract the vector for “man,” add the vector for “woman,” you get a point in space very close to… “queen.” The machine has learned, without anyone explicitly teaching it, that the relationship between king and queen is analogous to the relationship between man and woman.
How is this possible? During training, the model adjusts these embeddings so that tokens frequently appearing in similar contexts end up close to each other in this abstract space. It’s a kind of statistical cartography of meaning, where the position of each word is determined by the company it keeps.
These embeddings explain why LLMs can perform semantic analogies, understand metaphors, even translate between languages. They’ve constructed, through pure pattern observation, an internal representation of meaning that, while not identical to human understanding, captures remarkable structural aspects of language.
Yet this geometric representation of meaning raises unsettling questions. If intelligence can be reduced to distances in multidimensional space, to proximity calculations in an abstract universe, what does this say about the nature of understanding itself? Are we, too, navigating semantic spaces we’ve constructed through experience?
But how do these embeddings and this token prediction actually work in practice? Here we enter the heart of the machine, into the revolutionary architecture that made everything possible: the Transformer.
The Transformer: An architectural revolution
In 2017, a team of researchers at Google published a paper with a deceptively simple title: “Attention Is All You Need.” This seemingly modest phrase masked a technological earthquake that would transform the entire field of artificial intelligence. The paper introduced an architecture so elegant, so powerful, that it would become the foundation of virtually every major language model built since.
Before the Transformer, AI language models relied primarily on recurrent neural networks (RNNs), particularly their sophisticated variants like LSTMs (Long Short-Term Memory). These architectures processed text sequentially, word by word, like someone reading a book from beginning to end, carrying memory of what came before. But this sequential approach had crippling limitations.
The tyranny of sequence. Imagine trying to understand a long, complex sentence while only being able to remember, hazily, what came ten or fifteen words earlier. That was the curse of RNNs. Information diluted as it traveled through the network, making it nearly impossible to capture long-range dependencies in text. A pronoun at the end of a paragraph could barely “remember” its antecedent from the beginning.
The parallelization bottleneck. Because RNNs processed words one after another, they couldn’t take advantage of modern parallel computing architectures. Training was painfully slow, limiting the scale of models that could practically be built.
The Transformer blew these constraints apart with a deceptively simple idea: what if we could let every word in a sentence directly attend to every other word simultaneously?
The mechanism of Attention
At the heart of the Transformer lies this revolutionary mechanism called “attention.” Imagine you’re reading the sentence: “The cat, which was black and white, chased the mouse.” To understand this sentence, your brain doesn’t process it strictly left to right. Instead, you instantly recognize connections: “which” refers back to “cat,” “chased” connects to both “cat” and “mouse,” the color descriptions modify “cat.”
The attention mechanism allows the model to do something similar. For each word (or more precisely, each token), the model computes attention scores with all other words in the sequence. These scores determine how much each word should “pay attention” to every other word when building its understanding.
Here’s the technical beauty: these attention scores are computed through three learned representations for each token—Query, Key, and Value. Think of it like a library search:
- The Query is like asking “What information do I need?”
- The Key is like asking “What information do I have?”
- The Value is the actual information content
When a token’s Query matches another token’s Key, they have high attention—meaning they’re relevant to each other. The model then combines the Values of all relevant tokens, weighted by these attention scores, to build a rich, context-aware representation.
Multi-head attention takes this further by running multiple attention mechanisms in parallel, each potentially focusing on different types of relationships. One attention head might specialize in grammatical dependencies, another in semantic similarities, another in long-range narrative structure.
A Google Research study (2017) visualized how different attention heads specialize in a Transformer model:
- Head #1: Focuses on subject-verb relationships (92% accuracy)
- Head #3: Specialized in pronoun resolution (87% accuracy)
- Head #5: Detects relationships between named entities (79% accuracy)
Concrete example of coreference resolution: In the sentence “The animal didn’t cross the street because it was too tired,” the model correctly identified that “it” refers to “animal” and not “street” in a single computational step, unlike previous models that required multiple sequential steps.
This capability explains why Transformers excel at translating between languages with different grammatical genders, like French and English.
Source: “Attention Is All You Need” (2017), Attention Visualizations in Transformers (Google Research, 2018)
The Revolution of Parallelism and Its Consequences
This revolutionary architecture solves three major problems that had constrained artificial intelligence for decades, all at once.
First benefit: the end of the sequential bottleneck. All words are now processed simultaneously, in parallel, fully exploiting the power of modern processors. This parallelization transforms training that took months into processes of just weeks, making large-scale experimentation and rapid iterative improvement of models possible.
Second benefit: perfect capture of long-range dependencies. No more need to painfully “remember” the beginning of a sentence, hoping information doesn’t dilute along the way. Each word accesses all others directly and instantaneously, regardless of their distance in the text. This capability radically transforms the processing of long, complex, structured texts.
Third benefit: exceptional scalability. Transformers “scale” in a way that defies the usual laws of technology: the more data and computing power you give them, the better they perform, with no apparent plateau, no diminishing returns. This remarkable property explains why companies invest billions in ever-larger models, guided by the empirical conviction that performance will continue growing with scale.
Empirical results spectacularly confirm these theoretical promises. Upon its publication in 2017, the Transformer pulverizes all records in machine translation, achieving BLEU scores (the reference metric) of 28.4 on English-German translation and 41.8 on English-French. These numbers, technical in appearance, actually mark a qualitative leap: for the first time, machine translation reaches a quality level that makes its large-scale professional use possible.
But this is just the beginning. This architecture will rapidly spread to all domains of natural language processing, then beyond, to computer vision, graph analysis, computational biology. Transformers become the unifying architecture of modern artificial intelligence, the technical substrate upon which all major contemporary models are built.
Yet a revolutionary architecture isn’t enough. Because the most troubling secret of these systems doesn’t reside in their structure, but in what follows: a learning process so mysterious that even their creators sometimes struggle to explain why it works so well…
Tokens, the technical reality behind the metaphor
Before diving into the mysteries of training, it’s time to reveal a simplification I’ve deliberately maintained until now: LLMs don’t actually predict “words” in the traditional sense, but “tokens.” This technical distinction, far from being anecdotal, illuminates certain mysterious behaviors of these systems and explains several of their practical characteristics.
What exactly is a token? Imagine you had to cut up a sentence not into complete words as we naturally do, but into more subtle fragments that respect the internal logic of language. A token can be a complete word (“cat”), a word fragment (“eat-” from “eating”), a suffix (“-tion”), or even a simple character in some languages. This fragmentation, performed by algorithms called “tokenizers,” reveals hidden intelligence: it allows the system to generalize its linguistic understanding.
Let’s take a concrete example. The sentence “The cat eats a mouse” might be tokenized like this: [“The”, “cat”, “eat”, “s”, “a”, “mouse”]. This decomposition may seem artificial, but it hides deep logic: by separating “eats” into “eat” + “s”, the system can intuitively understand “eater,” “eating,” “eaten” without being explicitly taught English grammar rules.
Why does this distinction change everything? First, it explains LLM economics: when you use OpenAI’s API, you pay per token, not per word. “Hello” costs one token, “antidisestablishmentarianism” costs several. This asymmetry reflects the real computational complexity of processing.
Next, it illuminates context limits: the famous “128,000 tokens” of GPT-4 corresponds to roughly 80,000-100,000 French words depending on vocabulary complexity. This nuance is crucial for understanding true text processing capabilities.
Finally, it reveals subtle linguistic biases: English, optimized in most systems, generally requires fewer tokens than French to express the same idea. This technical asymmetry discreetly influences the multilingual performance of models.
The art of tokenization also explains why LLMs handle neologisms and technical terms so well: they recognize familiar fragments in unknown words, intuitively reconstructing meaning through morphological assembly. It’s this fine granularity that allows models to generalize beyond their training data with an ease that still surprises us.
This technical revelation takes nothing away from the magic of these systems. On the contrary, it reveals the hidden sophistication behind the apparent simplicity of “word prediction.” Token by token, these machines recompose the richness of human language with precision bordering on art.
But how does this token-by-token recomposition become possible? How do word fragments transform into apparent intelligence? This is where the most fascinating process of this entire technological revolution comes in: the training of language models.
The next part will take you where everything truly begins: to the heart of the learning process that transforms lines of code into troubling intelligence. This is where the machine, patiently, learns to speak… and to think.