
Manifold-Constrained Hyper-Connections (mHC)
Note: Cerise and Oscar don’t exist. They’re characters I created to make this topic more concrete, more alive. If you’re an expert in AI or cognitive psychology, you may find certain simplifications frustrating. That’s the price we pay for speaking to a broad audience. The references are there for those who want to dig deeper.
“Hey, Oscar, how does an artificial intelligence learn to think?“
Cerise, sitting cross-legged on the carpet, watched the rain trace furrows across the window. Oscar, immersed in reading a scientific paper, looked up. “That’s a big question, Cerise. Imagine you’re building a tower with Legos. Each Lego is a small piece of knowledge. To build a very tall, very intelligent tower, you need to stack thousands, millions of these Legos.“
“Easy!” she said.
“Not so fast,” Oscar smiled. “The taller the tower gets, the more fragile it becomes. The slightest draft can knock it down. That’s the great secret and the great problem for AI creators. They’re in a mad race to build taller and taller towers, but they keep hitting this wall: instability.“
This race for power is the one of large language models (LLMs). But today, it’s reaching its limits. A mysterious ailment, sudden “loss spikes,” derails months of training and wastes fortunes in computation. It’s in this context that a company named DeepSeek proposed a solution. An idea of rare elegance, hidden behind a name that seems straight out of a science fiction manual: Manifold-Constrained Hyper-Connections (mHC). This isn’t just an improvement; it’s a philosophical redesign of how information flows at the heart of an AI.
The Transformer and the mechanics of Attention
Before diving into the details of DeepSeek’s innovation, we need to understand the nature of the “machine” we’re trying to improve: the Transformer. Introduced in 2017 by Google researchers in the groundbreaking paper “Attention Is All You Need,” this architecture changed the face of AI.
“A Transformer, that’s the AI’s brain, right?” asked Cerise.
“Exactly. And its superpower is the attention mechanism,” Oscar replied. “Before Transformers, models read a sentence word by word, sequentially, like we do. It was slow and they tended to forget the beginning of the sentence by the time they reached the end. The Transformer, on the other hand, can look at all the words in a sentence at once.“
The attention mechanism allows the model, for each word, to “weigh” the importance of all other words in the sentence. For example, in the sentence “The cat drank the milk because it was thirsty,” when the model analyzes the word “it,” the attention mechanism enables it to understand that “it” refers to the “cat” and not the “milk.” It creates dynamic connections between words, regardless of their distance. It’s this ability to create long-range contextual links that made Transformers so powerful. The basic architecture of a Transformer is a stack of these attention layers, a bit like the floors of our Lego tower.
The paradox of depth and the ResNet revolution
Now, how do we stack these attention layers in a stable way? For that, we need to go back to 2015 and a paradox that baffled computer vision researchers. Theory suggested that a deeper network should perform better. Yet in practice, it was the opposite. Beyond a certain number of layers, a deep network achieved worse results than a shallower network. This is what the paper “Deep Residual Learning for Image Recognition” calls the degradation problem.
“Wait, Oscar,” Cerise interrupted. “It’s like if by adding floors to my Lego tower, it became not only more fragile, but also shorter? That’s absurd!“
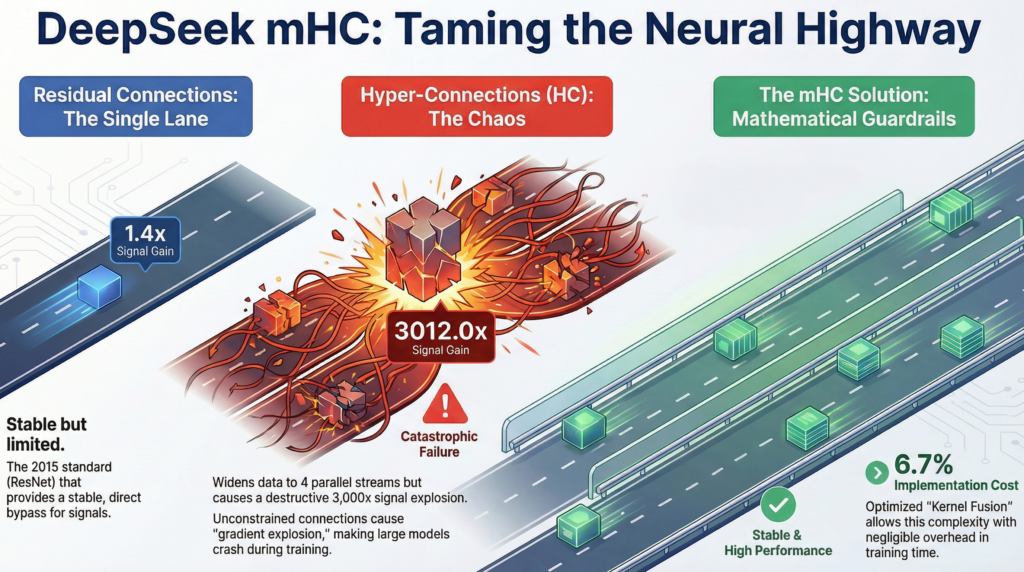
“That’s exactly the paradox,” Oscar confirmed. “The explanation is that the optimizer (the training algorithm) was unable to find the right path through this maze of layers. The solution by Kaiming He and his team was the residual connection (ResNet). The idea is disarmingly simple: create a “highway bypass” that allows the input signal to “jump” over a layer and be added directly to the output.“
This “shortcut” connection guarantees a fundamental property: identity mapping. It ensures that, in the worst case, if an additional layer contributes nothing, the optimizer can simply learn to ignore it and let the signal pass through intact. This idea was integrated at the heart of Transformers, becoming the backbone that allows their attention layers to be stacked.
Residual bottleneck and the failure of hyper-connections
However, when adapting this principle, the Transformer kept its Achilles’ heel: the “residual stream” remained a single-lane highway. All information is compressed and forced to flow through this same single channel, creating a bottleneck.
The most intuitive solution was to widen the highway. This is the principle of Hyper-Connections (HC), explored notably by ByteDance: creating multiple parallel information flows. But this freedom came at a terrible cost. By creating this multi-lane interchange without guardrails, the architects broke the golden rule of projection identity.
DeepSeek’s paper on mHC quantifies this chaos with frightening precision: the signal gain can reach peaks of nearly 3000 across layers. This runaway effect is a phenomenon of uncontrolled constructive interference. Numerically, this translates into “gradient explosion”: the calculated values become so large that they exceed the computer’s representation capacity, and training collapses.
Taming chaos through geometry and engineering
Faced with this failure, the DeepSeek team made a remarkably accurate diagnosis. The problem wasn’t the number of lanes, but the absence of clear rules to organize their interaction. Multiplying paths without a framework was like confusing richness with disorder.
Imagine a large public square. People can move freely, change direction, cross paths, speed up or slow down. But this freedom only exists because the square has borders, clearly defined entrances and exits. Without these boundaries, it would no longer be a square, but shapeless chaos.
This is exactly the type of framed freedom that the DeepSeek team sought to impose on information flows. Their solution, called Manifold-Constrained Hyper-Connections (mHC), consists of restoring a law of signal conservation by geometrically constraining how flows can combine.
The geometric “cage,” the Birkhoff polytope To achieve this, they force the matrices that govern exchanges between flows to belong to a particular mathematical structure, the Birkhoff polytope.
“A polytope? What’s that strange thing?” asked Cerise, a bit worried.
“It’s less intimidating than it seems,” Oscar reassured her. “Imagine a Rubik’s Cube. You can twist it in all directions, mix the colors, explore all possible configurations, but the cube remains a cube. It doesn’t collapse, it doesn’t deform. The Birkhoff polytope plays exactly this role for our connection matrices. It defines a space of allowed shapes within which they can evolve, but which they can never leave.”
More precisely, a Birkhoff polytope is the set of doubly stochastic matrices—matrices where each row and each column sums to exactly 1, and where all values are positive. This constraint is crucial: it guarantees that the total amount of information is preserved when passing from one layer to another.
The iterative algorithm: Sinkhorn-Knopp But how do we ensure that a matrix respects this rule? This is where DeepSeek employs a mathematical tool dating from 1967, the Sinkhorn-Knopp algorithm. Its purpose is to take any matrix and, through successive iterations, “massage” it until it becomes doubly stochastic.
“Imagine your matrix is a shapeless piece of modeling clay,” Oscar explained. “The Sinkhorn-Knopp algorithm is a very patient ‘masseur.’ It will first ‘massage’ all the rows so they have the right size. But in doing so, it slightly deformed the columns. So it will ‘massage’ the columns. But that slightly deformed the rows again… It repeats this process. After only 20 ‘massages,’ the matrix is close enough to the ideal shape to guarantee stability.“
The engineering challenge: kernel fusion Having a beautiful equation isn’t enough. The major challenge was implementing it without making the model unusable. The Sinkhorn-Knopp algorithm, being iterative, is a perfect candidate for the “memory wall.” This is where DeepSeek’s engineering work shines. Through low-level optimization techniques like kernel fusion, they grouped multiple operations into a single mega-instruction executed directly on the chip. The result is stunning: this sophisticated architecture adds only a computational overhead of just 6.7%.
Anatomy of a paradigm shift
At this point, something important has shifted. We’re no longer just talking about a more stable or more efficient model, but about a different way of thinking about the very construction of artificial intelligence.
The first consequence is almost counterintuitive; it challenges a belief that has become dominant.
The results published by DeepSeek show that the chaotic signal amplification, which could reach dizzying factors close to 3000, is brought down to a stable level of around 1.6. This restored stability doesn’t just prevent training collapse; it unleashes the model’s true potential. The gains observed on demanding reasoning tasks are significant, with notably a 7.2 point improvement on the BBH benchmark and 7.1 points on the GSM8K mathematics test.
These numbers tell a broader story. They show that performance no longer depends solely on the model’s raw size or the amount of computation deployed. Architecture becomes a variable in its own right, capable of producing more with less. This is a direct challenge to the scaling laws as they have dominated research in recent years.
The second implication touches on something deeper: the way an AI organizes its own internal work.
By stabilizing multiple parallel information flows, mHC opens the door to internal functional specialization. Where the single residual stream forced all information to mix in the same channel, this new structure allows us to imagine a true division of labor. One flow could focus on syntax, another on factual knowledge, yet another on abstract reasoning.
This hypothesis remains partly exploratory, but it’s conceptually powerful. It brings model architecture closer to certain intuitions from cognitive science, where specialization and coordination of functions play a central role. Intelligence doesn’t just arise from accumulation, but from organization.
Finally, this innovation isn’t just theoretical. It has very concrete effects on the real world.
In a sector where training the most advanced models costs hundreds of millions of dollars, an architecture capable of improving performance with a computational overhead limited to about 6.7% represents a considerable strategic advantage. It reduces dependence on brute force, lowers economic barriers, and can reshuffle the cards among actors capable of innovating on structure rather than on computational power alone.
In other words, DeepSeek hasn’t just made models more robust. They’ve shifted research’s center of gravity, from excess toward structure.
The Dawn of an Architectural Revolution
“So, if I’m summarizing correctly,” said Cerise, standing up, “the Transformer is a super-brain that looks at the whole sentence at once. To make it more powerful, we stack layers, but we need ‘highway bypasses’ (ResNet) so it doesn’t collapse. The problem is that it creates a bottleneck. So we tried to make a big interchange (HC), but that was anarchy. And DeepSeek finally succeeded by inventing a super-strict traffic code (mHC) so everything stays fluid and secure.“
“That’s exactly it,” Oscar concluded. “The mHC isn’t a replacement for the Transformer, but an evolution of how its layers are connected. It keeps the power of multiple flows while restoring the stability of classic connections.“
DeepSeek’s innovation is much more than a simple technical improvement; it’s the manifestation of a philosophical shift. For nearly a decade, AI research has been dominated by “brute force,” a race for size governed by scaling laws. The mHC reminds us that growth has physical limits and that intelligence doesn’t just arise from size, but also from the elegance of structure.
By solving a fundamental stability problem with a mathematical solution from the 1960s and cutting-edge software engineering, DeepSeek isn’t just proposing a new Lego brick; they’re proposing a new blueprint for the entire tower. It’s proof that the future of AI won’t only be played out in data centers overheated by ever-more-massive computations, but also in researchers’ creativity and architects’ ingenuity.
The question may no longer be how high we can stack the bricks, but how to design a tower that stands. A tower where each brick knows why it’s there, where forces are distributed, and where height is no longer a risky bet, but a natural consequence of structure.
The era of architectural intelligence is only beginning.
References
For meticulous minds, lovers of numbers and sleepless nights verifying sources, here are the links that nourished this article. They remind us of one simple thing: information still exists, as long as we take the time to read it, compare it, and understand it. But in the near future, this simple gesture may become a luxury, because as texts generated entirely by AIs multiply, the real risk is no longer disinformation, but the dilution of reality in an ocean of merely plausible content.
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention Is All You Need. Advances in Neural Information Processing Systems 30 (NIPS 2017).
- Turner, R. E. (2024). An Introduction to Transformers. arXiv:2304.10557v5 [cs.LG].
- He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep Residual Learning for Image Recognition. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
- Xie, Z., Wei, Y., Cao, H., et al. (2026). mHC: Manifold-Constrained Hyper-Connections. arXiv:2512.24880v2 [cs.CL]. DeepSeek-AI.
- Zhu, D., Huang, H., Huang, Z., et al. (2024). Hyper-Connections. arXiv:2409.19606 [cs.LG].
- Sinkhorn, R., & Knopp, P. (1967). Concerning nonnegative matrices and doubly stochastic matrices. Pacific Journal of Mathematics, 21(2), 343-348.
- Espinosa Mena, J. R. (2024). On the Convergence of the Sinkhorn-Knopp Algorithm with Sparse Cost Matrices. arXiv:2405.20528v3 [math.OC].
- Baumeister, B., & Ladisch, F. (2017). A property of the Birkhoff polytope. arXiv:1610.02077v2 [math.CO].
- Hoffmann, J., Borgeaud, S., Mensch, A., et al. (2022). Training Compute-Optimal Large Language Models. Advances in Neural Information Processing Systems 35.