
Picture a massive symphony orchestra filled with excellent musicians. They have everything: technique, ear, the habit of playing together. And yet, take away the conductor. Suddenly, something goes off.
Not because they become bad. On the contrary. Because each one does what they know how to do, as best they can, based on what they hear around them. The first violin takes initiative, the brass follows, the percussion anticipates, the woodwinds try to keep up. Sometimes, by miracle, everything synchronizes. You hear a common intention emerge, as if floating above the group. And sometimes, it falls apart. Each plays correctly, but not together. The music isn’t wrong, it’s unstable.
Large language models (LLMs) are like that. They’re systems capable of producing impressively high-quality text, with nuances, styles, reasoning, sometimes even a form of elegance. But they don’t have, by default, a single, stable intention. They react to context, pursue local coherence, optimize a plausible continuation. Result: they can produce an excellent answer, then, without warning, veer toward something fragile, approximate, or completely false, all while maintaining the same confident tone. It’s unsettling, because the form stays solid while the content can crack.
For a long time, we had two ways to take back control.
The first is prompt engineering. We try to guide the model with instructions, like we’d guide an improviser by giving them a theme, a role, a framework. We specify format, add constraints, define a tone. It often works, sometimes very well. But it remains indirect. We speak to the system’s input, hoping the inside follows faithfully. And so, yes, it’s sometimes capricious. Two similar phrasings can produce two very different behaviors.
The second is fine-tuning. There, we’re no longer talking about guiding, we’re talking about modifying. We retrain the model (or part of its parameters) so it adopts more reliable behavior on a given task. It’s effective, but it has a cost: you need data, computation, iterations, then maintenance over time. And there’s a real risk, that of gaining precision on one task while losing elsewhere, in flexibility, generality, or style quality.
And then there’s a third approach, more discreet, more surgical.
It starts from a simple idea: rather than rewriting everything, and rather than asking everything from the instruction text, why not intervene directly in what the model is “telling itself” while it calculates its response? Not at the level of the words it sees, but at the level of its internal states, where the answer is being constructed.
This is what’s often called steering.
How do we feed LLMs?
Before talking about steering, we need to understand what we’re steering.
An LLM is trained, initially, on a very repetitive task: predicting the next part of a text. We show it sequences, and ask it, over and over, which token comes next. This point seems almost childish, but it’s at the heart of everything. A model like GPT-3, for example, is an autoregressive model, it advances token by token, estimating at each step the most probable continuation given the context.
Put like that, it’s almost trivial. In practice, this constraint forces the model to learn enormous amounts of things “in the negative space.” To predict correctly, it must grasp grammar, co-occurrences, styles, dialogue structures, logical transitions, ways of arguing, turns of phrase that signal a hypothesis, an objection, a conclusion. It also captures factual regularities, in the sense that certain sequences recur often in the corpus, which allows it to produce answers that sound informed.
But there’s a flip side, and it’s structural.
The model doesn’t have, strictly speaking, a direct link to truth. It doesn’t observe the world, it observes texts. It learns statistical regularities from linguistic data, and it optimizes a probability of continuation. So it can produce a perfectly written, perfectly plausible answer, and yet false, because “plausible” and “true” aren’t the same thing. This gap is one of the entry points for the phenomenon often called hallucination: generated text can be fluid and convincing while being unfaithful to a source, or simply incorrect.
The term has been extensively studied in tasks like automatic summarization, where you can compare the output to the source document. In this context, research shows that models can introduce elements unsupported by the input, even when the style is impeccable.
I’m not citing this work to say that “everything hallucinates all the time,” but to establish a simple idea: the problem isn’t just a question of tone or caution, it also stems from the training objective and the fact that the model may prefer a plausible continuation to a verifiable one.
I want to emphasize one point: this isn’t an isolated bug, it’s a plausible consequence of the learning and generation mode. You can reduce the phenomenon, frame it, monitor it, and especially make it less dangerous through evaluation methods, information retrieval, safeguards, or steering. But we should avoid telling the story as if the model “knew” and then “lied.” The right mental image is rather: it produces the most coherent continuation with what it has seen, and sometimes this coherence imitates truth instead of guaranteeing it.
What happens in the model’s “Mind”
To understand steering, we need to introduce a term: activations.
When an LLM reads your sentence, it doesn’t “see” words in the human sense. It starts by transforming the text into internal units (tokens), then into vectors, meaning lists of numbers. Then, layer by layer, these vectors are transformed by the Transformer’s mechanisms (notably attention and feed-forward layers), until they produce a distribution over the next token.
We can picture this as a chain of processes, where each step keeps a sort of provisional memory of the situation. Not memory in the sense of “I remember yesterday,” rather an internal state that summarizes what the model has “understood” from the immediate context, and what it’s preparing as a plausible continuation.
In researchers’ vocabulary, these internal states, the intermediate outputs of the layers, are activations. They’re not all equivalent. Some correspond to the input after encoding, others to representations after attention, others to what comes out of the MLP blocks. In much interpretability work, we also talk about the residual stream, a vector flow that traverses the layers, to which contributions are successively added, layer after layer.
Why does this matter? Because the model doesn’t “decide” all at once. The response is built progressively in this vector space. A nuance of tone, an implicit constraint, an argumentative direction, all that doesn’t appear in a single block. It settles in, reinforces, combines, sometimes contradicts itself, and in the end, the text emerges as the visible surface of all this internal cooking.
These intermediate states are, roughly speaking, activations.
This is where everything shifts.
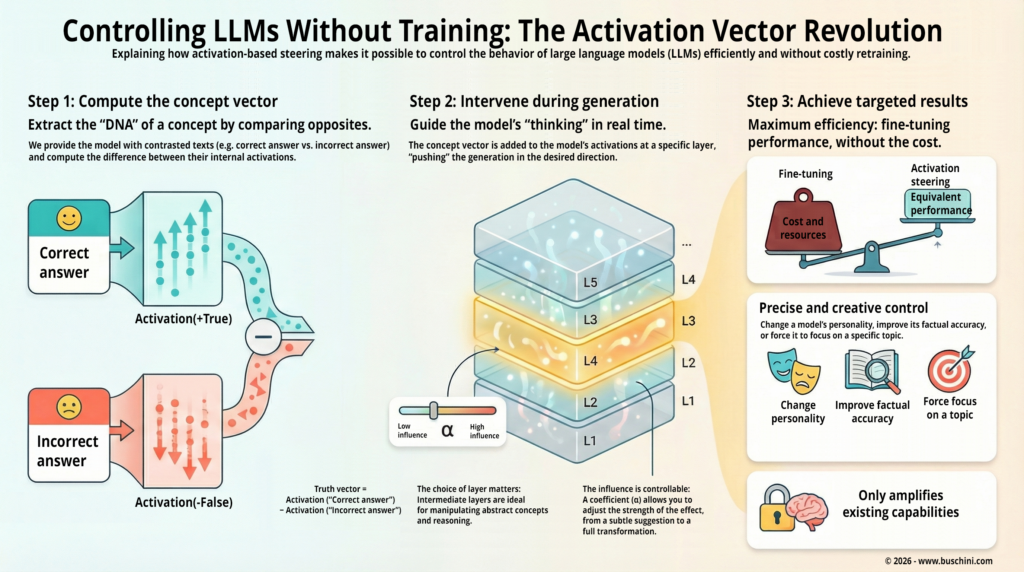
If we can observe, extract, compare activations, then we can also, in principle, modify them. Not by changing the model’s weights, that would be another category of intervention. But by adding a small signal, a “direction,” in the right place, at the right time, during inference. This is exactly the intuition behind activation addition, where we add a steering vector to activations to orient the model’s behavior, without optimization and without retraining the weights.
We need to be precise about what this implies. Modifying activations isn’t injecting a logical rule into the model. It’s not giving it knowledge it doesn’t have either. It’s rather increasing the probability that the model takes one internal trajectory rather than another, by amplifying a certain “mode” of continuation already accessible.
Steering, or the art of intervening during thought
So here’s the basic scenario.
You have a language model that responds to your prompts. It works, but you’d like it to adopt a particular behavior more reliably: being more cautious in its answers, following stricter reasoning steps, avoiding certain stylistic patterns. You could rephrase your prompt a hundred times, hoping to hit the right formulation. You could fine-tune the model, if you have the resources. Or you could do something more direct.
You isolate an internal state, an activation vector at a specific layer. You construct what researchers sometimes call a steering vector, often by taking the difference between activations in two contrasting contexts (for example, answers with caution versus answers without caution). Then you add this vector, during inference, to the model’s activations as it generates its response.
The effect can be immediate. Without retraining anything, without modifying prompts, the model’s behavior shifts toward what this vector encodes.
This isn’t magic. It’s an architectural consequence. The model functions by accumulating internal transformations, and these transformations leave manipulable traces. By adding an oriented vector, you increase the weight of certain internal representations, you amplify certain “paths” that the model could already take, but which weren’t necessarily dominant.
The simplest method, often presented as a baseline, is activation addition, used for example in the work of Turner et al. (2023). The idea is elementary: find the activations that correspond to the desired behavior, construct a direction vector from them, then add this vector during generation. No optimizer, no new training phase, just a targeted numerical intervention.
The advantage is accessibility. If you have access to the model’s activations (which is often the case with open models or via instrumented APIs), you can test very quickly. You generate examples that embody the behavior you want, you observe what changes internally, you extract a direction, you apply it.
The limit is just as visible. The method is empirical. You’re manipulating vectors whose meaning isn’t always transparent. Sometimes it works magnificently, sometimes it produces side effects: an excessive tone, a loss of fluidity, inconsistencies. It depends on the choice of layers, the magnitude of the vector, the stability of internal representations. This isn’t a recipe with guaranteed success, it’s an exploration space.
But there’s a crucial point. This empiricism is also an asset. Because it means you can iterate, test, correct, without needing to mobilize heavy infrastructure. You stay in “experimental mode.” If a direction doesn’t work, you abandon it. If it works partially, you refine it. And progressively, you build an intuition of what works and what doesn’t for a given model, a given task, a given style of intervention.
There are also more sophisticated variants.
Some approaches introduce vectors constructed not by difference, but by projection or combination of latent subspaces. Others modulate the amplitude continuously depending on context. Still others try to intervene not at a single layer, but at several, orchestrating a kind of coordinated internal pressure.
One notable method is what the authors of the recent Sinii et al. (2025) paper call “Bias-Only Adaptation.” The idea is simple but effective. Instead of modifying millions of model parameters, you intervene only on bias vectors, those small constant terms that are added in certain layers. The cost is much lower, the intervention remains targeted, and yet it’s often enough to significantly steer behavior. The paper shows, on several tasks, that you can obtain close or superior performance to heavier fine-tuning, while maintaining better generalization and requiring much less compute.
What’s interesting in this work isn’t just the result, it’s the positioning. The authors explain that by focusing the intervention on a restricted set of parameters, you avoid destabilizing the complex internal equilibria built during the model’s training. You touch less, you disturb less, and paradoxically, you steer better.
This aligns with a broader intuition: the model already has the capacity to respond in different ways. It’s not about adding new knowledge, but about favoring certain existing internal paths. And to favor a path, you don’t always need to modify the entire system, sometimes a well-placed nudge is enough.
This might seem abstract. Let me make it more concrete.
Imagine you use an LLM to generate product descriptions. The model is very good, but sometimes it gets carried away, exaggerates, uses superlatives a bit too easily. You could spend hours polishing your instructions, adding examples, hoping the model internalizes the nuance. Or you could construct a steering vector that encodes a “sober, factual, without emphasis” mode. You extract this vector from contrasting examples: enthusiastic responses versus neutral responses. Then you add it to the model’s internal activations during generation. The tone changes. Not always perfectly, not always uniformly, but often enough to be useful.
Another example, more sensitive: imagine you want the model to be systematically more cautious when it’s unsure. You construct a steering vector that amplifies “uncertainty patterns,” those that lead the model to say “I’m not certain” rather than improvising a plausible answer. You inject this vector at the right layers. The model becomes less assertive when the context is ambiguous. It doesn’t always work, there can be side effects (too much hesitation, overly cautious tone), but the principle is there: you intervene on the internal equilibrium, not just on the surface of the text.
This isn’t a magic wand. It’s a tool, and like any tool, it requires judgment. You have to choose your layers, calibrate your vectors, test on varied cases, accept that an intervention that works on one type of task may fail on another. But what’s gained is control that’s more direct than via prompts, and less costly than via complete fine-tuning.
And above all, you stay agile. You can multiply tests, adjust hypotheses, combine several vectors if necessary, all without needing to restart a training process from scratch each time.
What we actually touch
We can act on activations, very well. But do we understand what these activations “contain”?
Because in practice, when you apply a steering vector, you’re making a gesture that sometimes works very well, and sometimes much less so. Now, as long as you don’t know exactly what you’ve touched, you remain in a logic of empirical tuning. You adjust, you observe, you start again. It’s useful, but it’s difficult to make reliable as soon as you leave demos.
This is where sparse autoencoders (SAEs) come in, in a current often called mechanistic interpretability. The goal isn’t to make the model “transparent” in the naive sense, as if we could read an internal thought like we read a sentence. The goal is more concrete: find better “objects” of analysis than the isolated neuron. Anthropic researchers defend the idea that a neuron taken alone is often a bad candidate, because it can mix several concepts, what they describe under the term superposition. So they propose working with learned units, which they call features, obtained through a form of dictionary learning via SAEs.
The intuition is as follows.
An SAE takes an activation vector (for example, at a precise location in the model) and learns to reconstruct it from a set of internal components. The “sparse” constraint is that, for a given input, only a few components should activate strongly. Put simply, we’re looking for a decomposition where most “features” stay off, and where a few light up clearly, which makes the whole more interpretable.
This point is important, because it explains the real ambition of SAEs: they don’t claim to “explain the model” entirely. They try to provide a more readable intermediate representation, an alphabet of internal concepts, at least partially separated from each other.
From there, the idea that makes eyes light up is quite natural.
If you can identify features associated with certain output patterns, caution, aggressiveness, step-by-step reasoning, references to a content category, then you can imagine cleaner steering. Instead of pushing an empirical direction constructed by average difference, you could act on better characterized features: reinforce some, attenuate others, and measure what changes. We’d progressively move from gut-feeling steering to more instrumented steering.
Caution, we need to remain careful about the maturity level.
Even in work that shows impressive results, authors talk about research tools and analyses on specific models or locations, not a universal dashboard ready to plug in everywhere. And one difficulty remains central: an “interpretable” feature isn’t automatically a “controllable” feature without side effects. There’s now work that focuses precisely on the sensitivity of learned features and on the risks of poor generalization when we intervene.
So yes, SAEs give a very serious lead: better understand what we’re touching when we touch an activation, and link steering to a more stable internal cartography. But we need to keep the right posture: it’s an active direction, promising, still under construction, with real successes, and open questions about robustness, generalization, and the safety of interventions.
The digital mirror
What steering changes, fundamentally, isn’t just a technique.
It’s a relationship.
Until now, most uses of LLMs resembled a conversation. We ask a question, refine an instruction, rephrase, insist. We learn to speak better to the model, hoping it responds better to us. Control passes through language.
With steering, we enter another zone. We no longer just interrogate, we begin to tune. Sometimes very finely, sometimes in real time. We no longer just seek an answer, we seek an answer posture. A mode of caution. A way of arguing. A tonality. A style of reasoning. And this shift, even if it remains technical, has something psychological about it.
Because from the moment we know that a model can be pushed in one internal direction rather than another, we stop seeing it as a simple “text engine.” We begin to see it as a system that possesses several possible pathways, several ways of arriving, and that these ways can be favored. It’s not proof of intention. It’s not proof of understanding in the human sense. But it’s a practical fact: visible behavior depends on internal trajectories, and these trajectories can be inflected.
And what’s troubling is the reflexive return.
By dint of talking about activations, directions, internal biases, we find ourselves looking at our own minds with similar words. Not because brain and LLM would be identical, they’re not, but because the comparison forces clarification.
An LLM doesn’t think “with sentences.” It manipulates internal states that evolve, then produces text as a final result. And we, if we’re honest, often do the opposite. We believe our thoughts are sentences because that’s what our consciousness catches best, the inner sentence, the little narration we tell ourselves. But the sentence is often the top floor. Below, there are tendencies, emotions, associations, heuristics, impulses, resistances. A state, before discourse.
Steering makes this idea hard to avoid: text isn’t thought, it’s an output. Even in us. Text is sometimes the clean facade of a much more moving state. And when we see a model produce a very assured sentence while the content may be fragile, we understand how much we too can confuse the quality of a formulation with the solidity of an idea.
We need to stay clear on the limits.
Steering doesn’t explain consciousness. It proves nothing about humans. It doesn’t say that “thinking” boils down to vectors. It only says, and this is already a lot, that a system can produce very different outputs depending on how its internal state is oriented.
And from there, a question imposes itself, uninvited.
When we “change our minds,” what exactly changes? The sentence we pronounce, or the internal equilibrium that makes this sentence possible? And if this equilibrium moves, under the effect of an experience, an emotion, a conversation, a detail, then perhaps freedom isn’t a switch, but a dynamic. A trajectory, too, that can be influenced, oriented, fragile.
References
For meticulous minds, lovers of numbers and sleepless nights verifying sources, here are the links that nourished this article. They remind us of one simple thing: information still exists, provided one takes the time to read it, compare it, and understand it. But in the near future, this simple gesture may become a luxury, because as texts generated entirely by AI multiply, the real risk is no longer disinformation, but the dilution of reality in an ocean of merely plausible content.
- Sinii, V. et al. (2025). Steering LLM Reasoning Through Bias-Only Adaptation. arXiv:2505.18706v3.
- Turner, A. et al. (2023). Activation Addition: Steering LMs without Optimization.
- Bricken, T. et al. (2023). Towards Monosemanticity: Decomposing Language Models With Dictionaries.
- Hubinger, C. (2024). A Toy Model of Steering.
- Olah, C. et al. (2020). An Overview of Early Vision in InceptionV1.