
L’entraînement et l’émergence ou la naissance d’une intelligence
Dans l’épisode précédent, Cerise apprenait que ce qu’elle prenait pour une pensée n’était qu’une prédiction habile, sculptée dans les probabilités. Mais pour comprendre vraiment cette magie, il lui faut plonger plus loin : au cœur du processus d’entraînement qui donne à Ada sa puissance et sa personnalité.
Entre 2018 et 2022, dans le secret des laboratoires, comprendre l’architecture des Transformers n’est que la première étape de notre voyage au cœur de l’intelligence artificielle moderne. Car une architecture, aussi révolutionnaire soit-elle, n’est qu’une coquille vide sans le processus qui lui donne vie : l’entraînement. C’est là que réside peut-être le mystère le plus profond de ces systèmes, celui qui fait que des matrices mathématiques deviennent capables de composer des poèmes, de résoudre des équations, de mener des conversations d’une sophistication troublante.
Le grand « gavage »
L’entraînement d’un Large Language Model commence par ce que les chercheurs appellent avec une pointe d’ironie le « gavage industriel à une échelle absolument hallucinante ». Imaginez une créature numérique dotée d’un appétit insatiable pour les mots, les phrases, les textes de toute nature et de toute provenance. Cette créature va littéralement dévorer une bonne partie de la production écrite de l’humanité : l’intégralité de Wikipedia dans toutes les langues, des millions de livres numérisés, des téraoctets d’articles de journaux, des forums de discussion, des conversations sur les réseaux sociaux, des codes informatiques dans tous les langages de programmation, des documents scientifiques, des œuvres littéraires, des manuels techniques…
Cette phase de pré-entraînement ressemble à l’éducation d’un enfant prodige qui apprendrait à parler non pas en écoutant ses parents, mais en absorbant simultanément toute la littérature mondiale, tous les journaux jamais publiés, toutes les conversations jamais tenues. Un apprentissage d’une intensité et d’une ampleur qui dépassent tout ce que l’évolution humaine a jamais produit.
Mais attention, le modèle ne mémorise pas ces textes au sens où nous mémorisons un poème ou une chanson. Il opère une abstraction beaucoup plus subtile et puissante : il apprend les patterns sous-jacents, les régularités cachées, les structures invisibles qui gouvernent le langage humain. C’est comme si, en lisant des millions de partitions musicales, quelqu’un développait une compréhension intuitive de l’harmonie, du rythme, de la mélodie, sans pour autant retenir note par note chaque composition étudiée.
Le processus d’apprentissage lui-même est d’une simplicité conceptuelle désarmante. On présente au modèle une phrase incomplète, disons « Le chat dort sur le… », et on lui demande de deviner le mot suivant. S’il propose « tapis », et que la vraie suite était effectivement « tapis », il reçoit une « récompense » mathématique. S’il propose « réfrigérateur », la « punition » l’incite à ajuster ses paramètres internes pour faire mieux la prochaine fois.
Répétez cette opération des trillions de fois avec des trillions de phrases différentes, mobilisez des fermes entières de processeurs pendant des semaines, et quelque chose d’extraordinaire émerge de cette répétition industrielle : le modèle développe une compréhension intuitive du langage qui dépasse largement la simple prédiction de mots. Il saisit les nuances stylistiques, maîtrise la logique argumentative, absorbe des connaissances factuelles, développe une sensibilité aux contextes culturels.
Quand la machine apprend l’humanité
Mais voilà le paradoxe troublant : un modèle simplement entraîné à prédire le mot suivant ne produit pas nécessairement des réponses utiles, honnêtes ou bienveillantes. Il reproduit fidèlement ce qu’il a observé sur Internet… y compris le pire de la nature humaine. Les premiers prototypes de ChatGPT, avant leur « civilisation », pouvaient tenir des propos toxiques, répandre des théories conspirationnistes, adopter des biais discriminatoires. Ils reflétaient Internet dans toute sa diversité, y compris ses zones d’ombre.
C’est là qu’intervient une innovation cruciale qui a rendu possible l’émergence de systèmes comme ChatGPT : le RLHF (Reinforcement Learning from Human Feedback), l’apprentissage par renforcement avec feedback humain. Cette phase, plus discrète mais tout aussi essentielle, consiste à « civiliser » le modèle, à lui enseigner les valeurs, les normes, les comportements souhaitables.
Le processus ressemble à l’éducation d’un adolescent brillant mais mal dégrossi. On fait générer des réponses au modèle sur des milliers de questions variées, puis des humains, ces fameux travailleurs souvent sous-payés dans des pays en développement qui jouent un rôle crucial mais invisible dans cette révolution, évaluent et classent ces réponses. « Cette réponse est utile et respectueuse », « celle-ci est factuelle mais froide », « cette troisième est créative mais inappropriée »…
Ces évaluations humaines servent ensuite à réentraîner le modèle selon une logique de renforcement. C’est exactement comme dresser un animal très intelligent : quand il adopte un comportement souhaité, il reçoit une récompense qui renforce la probabilité qu’il reproduise ce comportement. Quand il fait quelque chose d’inapproprié, la « punition » mathématique l’incite à éviter ce type de réponse à l’avenir.
Cette phase d’alignement transforme un générateur de texte brut en assistant conversationnel poli, utile, et généralement bienveillant. C’est elle qui fait que ChatGPT s’excuse quand il se trompe, demande des clarifications quand une question est ambiguë, refuse de participer à des activités potentiellement nuisibles.
L’ENTRAÎNEMENT DES LLM EN CHIFFRES
L’entraînement de GPT-4 illustre l’ampleur industrielle du processus :
- Volume de données : Estimé à plus de 13 000 milliards de tokens (équivalent à environ 10 millions de livres)
- Coût d’entraînement : Entre 100 et 200 millions de dollars
- Puissance de calcul : Plus de 25 000 GPU A100 pendant plusieurs mois
- Énergie consommée : Équivalente à la consommation annuelle d’environ 1 000 foyers américains
Pour l’alignement (RLHF) :
- Plus de 20 000 heures de travail humain pour évaluer les réponses
- Environ 1 million de paires de réponses classées par des humains
- Réduction de 63% des hallucinations par rapport aux versions non alignées
Sources: OpenAI (2023), Anthropic (2024), Études sur l’empreinte carbone des LLM (2024)
Les trois modalités d’intelligence artificielle
Une fois cette double éducation achevée, gavage informationnel puis civilisation comportementale, le modèle développe une polyvalence remarquable qui se manifeste selon trois modalités distinctes, chacune révélant un aspect différent de l’intelligence artificielle émergente.
L’apprentissage zéro-shot révèle peut-être l’aspect le plus mystérieux de ces systèmes. Sans aucun exemple préalable, sans préparation spécifique, le modèle peut accomplir des tâches pour lesquelles il n’a jamais été explicitement entraîné. « Traduis cette phrase en mandarin », « Résume cet article de recherche en génétique », « Écris un haïku sur la solitude urbaine », « Explique la relativité générale à un enfant de dix ans »… Dans chaque cas, le modèle puise dans sa compréhension générale du langage et de la connaissance pour produire des réponses pertinentes et souvent remarquables.
C’est comme un étudiant exceptionnellement doué qui arrive à un examen dans une matière qu’il n’a jamais formellement étudiée, mais s’en sort brillamment grâce à sa culture générale, sa capacité d’analyse et son intuition. Cette capacité de généralisation révèle que l’entraînement sur la prédiction de mots a développé des compétences cognitives bien plus larges et profondes que ne le suggère la simplicité apparente de la tâche d’origine.
L’apprentissage few-shot pousse cette capacité d’adaptation encore plus loin. Montrez quelques exemples au modèle, trois emails formels transformés en versions familières, quatre équations mathématiques avec leurs solutions, cinq poèmes classiques adaptés au langage contemporain, et il saisit immédiatement le pattern, comprend la transformation attendue, et l’applique à de nouveaux cas avec une précision stupéfiante.
Cette modalité révèle une forme d’intelligence particulièrement troublante : la capacité à apprendre des règles complexes à partir d’exemples minimaux. Imaginez expliquer à quelqu’un les règles du bridge avec seulement trois mains jouées, ou enseigner les subtilités de la poésie classique française avec quatre sonnets… C’est exactement ce que font les LLM modernes, avec une aisance qui défie notre compréhension de l’apprentissage.
Le fine-tuning représente la forme la plus intensive d’adaptation, comparable à une spécialisation universitaire après des études générales. On réentraîne spécifiquement le modèle sur une tâche précise avec des milliers d’exemples étiquetés. Cette approche produit des systèmes hyperspécialisés : des modèles médicaux capables de diagnostiquer des pathologies rares, des assistants juridiques qui analysent des contrats avec la précision d’un avocat senior, des outils de programmation qui génèrent du code professionnel dans des langages obscurs.
Quand le tout dépasse la somme des parties
Mais voici le phénomène le plus troublant, celui qui défie notre compréhension et remet en question nos certitudes sur la nature de l’intelligence : l’émergence. À partir d’un certain seuil de complexité, nombre de paramètres, quantité de données, puissance de calcul, des capacités inattendues apparaissent spontanément, sans avoir été explicitement programmées ou enseignées.
Ce que les créateurs de GPT-3 ont découvert les a surpris : leur système, entraîné uniquement à prédire le mot suivant, s’était spontanément mis à faire des mathématiques avancées. Personnne ne lui avait appris les équations, pourtant il résolvait des problèmes complexes. Personne ne lui avait enseigné la logique formelle, pourtant il menait des raisonnements sophistiqués. Personne ne lui avait donné de cours de programmation, pourtant il codait dans des dizaines de langages.
La révélation la plus troublante ? Ces compétences n’étaient pas des ajouts programmés mais des propriétés émergentes qui surgissaient naturellement quand le système atteignait une taille critique. C’est un peu comme si, en apprenant suffisamment de recettes de cuisine en observant des chefs à l’œuvre, quelqu’un développait spontanément une compréhension profonde de la chimie alimentaire, de la nutrition, de l’art culinaire, et même de l’agriculture.
Cette émergence explique en partie pourquoi même les créateurs de ces systèmes sont parfois surpris par leurs capacités. OpenAI a découvert certaines aptitudes de GPT-4 après sa création, en l’explorant comme on explore un continent inconnu.
L’émergence n’est pas une simple montée en puissance, c’est un phénomène qui déroute, même ceux qui l’ont déclenché. Car il y a quelque chose d’inattendu dans le comportement de ces modèles : ils développent des compétences que personne ne leur a explicitement enseignées. Et parfois, ce sont les ingénieurs eux-mêmes qui découvrent, stupéfaits, ce que leur créature est devenue capable de faire.
- Les mathématiques spontanées : En 2020, OpenAI observe que GPT-3, pourtant entraîné uniquement sur du texte, commence à résoudre des équations différentielles complexes. Aucun module dédié, aucun cours intégré. Comme si, en lisant des milliers d’articles scientifiques, le modèle avait fini par absorber une forme d’intuition mathématique.
- La traduction entre langages informatiques : Sans entraînement spécifique, GPT-3 est capable de convertir du code Python en JavaScript, puis en SQL. Il semble avoir identifié des structures logiques communes, comme s’il pressentait une grammaire universelle du code, au-delà des langages eux-mêmes.
- L’auto-amélioration par le dialogue : En posant une simple question du type “Comment pourrais-je améliorer ce prompt ?”, les développeurs découvrent que GPT-4 propose des stratégies de formulation qu’eux-mêmes n’avaient pas envisagées. L’outil devient consultant de son propre usage.
- La créativité sous contrainte : Demandez à ChatGPT d’écrire un sonnet où chaque vers commence par une lettre différente de l’alphabet et contient exactement sept mots. Il le fait. Et le résultat tient debout. Non pas par hasard, mais avec une rigueur poétique qui trouble les auteurs chevronnés.
- L’intuition émotionnelle : Sans formation en psychologie, GPT-4 détecte parfois, dans une phrase banale, une détresse sous-jacente, une tension affective implicite. Et formule une réponse d’une douceur inattendue, comme si quelque chose en lui savait écouter au-delà des mots.
- Et parfois, l’oubli inexplicable : Le plus troublant, peut-être, est ce que les chercheurs appellent le paradoxe de l’émergence non linéaire. GPT-4 excelle sur certains tests de logique. Puis une version ultérieure, GPT-4.5, s’y montre moins performante. Aucune modification visible dans l’architecture, aucun changement clair dans les données. Et pourtant, des capacités apparaissent, puis s’évanouissent. Comme si ces modèles avaient leur propre météo cognitive.
Cette imprévisibilité de l’intelligence artificielle, fascinante autant qu’inquiétante, nous rappelle que nous sommes peut-être en train de créer quelque chose qui nous dépasse déjà.
Mais comment expliquer ce mystère ? Et surtout, jusqu’où peut aller cette émergence ? La réponse à cette question pourrait déterminer l’avenir même de notre espèce…
Cependant, cette même imprévisibilité qui rend ces systèmes si fascinants soulève un paradoxe troublant. Si nous ne comprenons pas entièrement comment émergent leurs capacités les plus remarquables, comment pouvons-nous anticiper leurs défaillances ? Si leurs créateurs découvrent après coup des aptitudes inattendues, quelles autres surprises, moins réjouissantes cette fois, nous réservent-ils ?
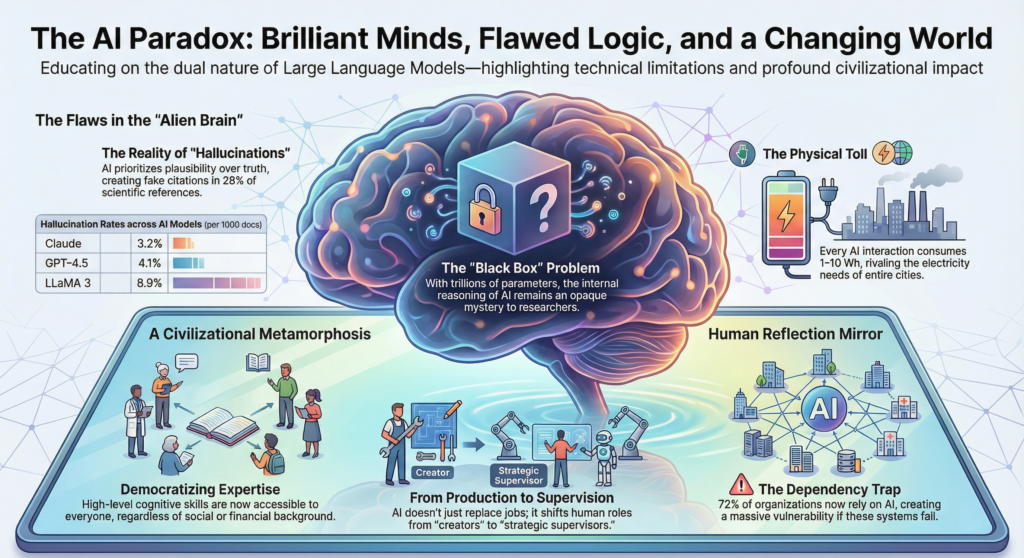
Car derrière l’éblouissement de l’émergence se cachent des zones d’ombre tout aussi mystérieuses : des hallucinations plausibles, des biais invisibles, des comportements erratiques que personne n’a programmés mais qui surgissent spontanément de la complexité du système. L’émergence, c’est aussi cela : l’apparition de propriétés qu’on n’avait ni prévues ni désirées.
Il convient donc, avant de nous projeter vers ces horizons vertigineux, de garder les pieds sur terre et d’examiner lucidement ces limites bien réelles. Car si leur potentiel émergent fascine, leurs défaillances actuelles rappellent qu’ils restent des créations imparfaites, aux comportements parfois déconcertants.
La quatrième partie ouvre une brèche plus inquiétante : que se passe-t-il lorsque l’intelligence artificielle devient un miroir aux reflets trompeurs ? Hallucinations, biais, opacité… Ce que vous allez lire pourrait bien vous faire douter de vos propres certitudes.