
Vous voyez un orchestre symphonique immense, rempli de musiciens excellents. Ils ont tout, la technique, l’oreille, l’habitude de jouer ensemble. Et pourtant, enlevez le chef. D’un coup, quelque chose se dérègle.
Pas parce qu’ils deviennent mauvais. Au contraire. Parce que chacun fait ce qu’il sait faire, au mieux, à partir de ce qu’il entend autour de lui. Le premier violon prend une initiative, les cuivres suivent, les percussions anticipent, les bois tentent de recoller. Parfois, par miracle, tout se synchronise. On entend une intention commune émerger, comme si elle flottait au-dessus du groupe. Et parfois, ça se délite. Chacun joue juste, mais pas ensemble. La musique n’est pas fausse, elle est instable.
Les grands modèles de langage (les llm) ressemblent à ça. Ce sont des systèmes capables de produire du texte d’une qualité impressionnante, avec des nuances, des styles, des raisonnements, parfois même une forme d’élégance. Mais ils n’ont pas, par défaut, une intention unique et stable. Ils réagissent au contexte, ils poursuivent une cohérence locale, ils optimisent une suite plausible. Résultat, ils peuvent sortir une réponse excellente, puis, sans prévenir, déraper vers quelque chose de fragile, d’approximatif, ou de complètement faux, tout en gardant le même ton assuré. C’est déroutant, parce que la forme reste solide alors que le fond peut se fissurer.
Pendant longtemps, on a eu deux manières de reprendre la main.
La première, c’est le prompt engineering. On essaie de guider le modèle avec des instructions, comme on guiderait un improvisateur en lui donnant un thème, un rôle, un cadre. On précise le format, on ajoute des contraintes, on définit un ton. Ça fonctionne souvent, parfois très bien. Mais ça reste indirect. On parle à l’entrée du système, en espérant que l’intérieur suive fidèlement. Et donc, oui, c’est parfois capricieux. Deux formulations proches peuvent produire deux comportements très différents.
La seconde, c’est le fine-tuning. Là, on ne parle plus d’orienter, on parle de modifier. On réentraîne le modèle (ou une partie de ses paramètres) pour qu’il adopte un comportement plus fiable sur une tâche donnée. C’est efficace, mais ça a un coût : il faut des données, du calcul, des itérations, puis maintenir tout ça dans le temps. Et il y a un risque réel, celui de gagner en précision sur une tâche, et de perdre ailleurs, en flexibilité, en généralité, ou en qualité de style.
Et puis il y a une troisième approche, plus discrète, plus chirurgicale.
Elle part d’une idée simple : plutôt que de tout réécrire, et plutôt que de tout demander au texte d’instructions, pourquoi ne pas intervenir directement dans ce que le modèle est en train de “se raconter” pendant qu’il calcule sa réponse ? Pas au niveau des mots qu’il voit, mais au niveau de ses états internes, là où se fabrique la réponse.
C’est ce qu’on appelle souvent le steering, qu’on peut traduire ici par pilotage.
Comment nourrit-on les LLM ?
Avant de parler pilotage, il faut comprendre ce qu’on pilote.
Un llm est entraîné, au départ, sur une tâche très répétitive : prédire la suite d’un texte. On lui montre des séquences, et on lui demande, encore et encore, quel token vient après. Ce point paraît presque enfantin, mais il est au cœur de tout. Un modèle comme GPT-3, par exemple, est un modèle auto-régressif, il avance token par token, en estimant à chaque étape la suite la plus probable au regard du contexte.
Dit comme ça, c’est presque trivial. En pratique, cette contrainte force le modèle à apprendre énormément de choses “en creux”. Pour prédire correctement, il doit saisir la grammaire, les cooccurrences, les styles, les structures de dialogue, les transitions logiques, les manières d’argumenter, les tournures qui signalent une hypothèse, une objection, une conclusion. Il capte aussi des régularités factuelles, au sens où certains enchaînements reviennent souvent dans les corpus, ce qui lui permet de produire des réponses qui sonnent informées.
Mais il y a un revers, et il est structurel.
Le modèle n’a pas, au sens strict, un lien direct à la vérité. Il n’observe pas le monde, il observe des textes. Il apprend des régularités statistiques sur des données linguistiques, et il optimise une probabilité de continuation. Donc il peut produire une réponse parfaitement rédigée, parfaitement plausible, et pourtant fausse, parce que “plausible” et “vrai” ne sont pas la même chose. Ce décalage est l’une des portes d’entrée du phénomène qu’on appelle souvent hallucination : un texte généré peut être fluide et convaincant, tout en étant non fidèle à une source, ou tout simplement incorrect.
Le terme a été beaucoup étudié dans des tâches comme le résumé automatique, où l’on peut comparer la sortie au document source. Dans ce cadre, des travaux montrent que des modèles peuvent introduire des éléments non étayés par l’entrée, même quand le style est impeccable. Je ne cite pas ces travaux pour dire que “tout hallucine tout le temps”, mais pour fixer une idée simple : le problème n’est pas seulement une question de ton ou de prudence, il tient aussi à l’objectif d’entraînement et au fait que le modèle peut préférer une continuation plausible à une continuation vérifiable.
J’insiste sur un point : ce n’est pas un bug isolé, c’est une conséquence plausible du mode d’apprentissage et de génération. On peut réduire le phénomène, le cadrer, le surveiller, et surtout le rendre moins dangereux par des méthodes d’évaluation, de récupération d’information, de garde-fous, ou de pilotage. Mais il faut éviter de raconter l’histoire comme si le modèle “savait” puis “mentait”. La bonne image mentale, c’est plutôt : il produit la suite la plus cohérente avec ce qu’il a vu, et parfois cette cohérence imite la vérité au lieu de la garantir.
Ce qui se passe dans la “tête” du modèle
Pour comprendre le steering, il faut poser un mot, les activations.
Quand un llm lit votre phrase, il ne “voit” pas des mots au sens humain. Il commence par transformer le texte en unités internes (des tokens), puis en vecteurs, c’est-à-dire des listes de nombres. Ensuite, couche après couche, ces vecteurs sont transformés par les mécanismes du Transformer (notamment l’attention et les couches feed-forward), jusqu’à produire une distribution sur le prochain token.
On peut se représenter ça comme une chaîne de traitements, où chaque étape garde une sorte de mémoire provisoire de la situation. Pas une mémoire au sens “je me souviens d’hier”, plutôt un état interne qui résume ce que le modèle a “compris” du contexte immédiat, et ce qu’il est en train de préparer comme continuation plausible.
Dans le vocabulaire des chercheurs, ces états internes, les sorties intermédiaires des couches, ce sont les activations. Elles ne sont pas toutes équivalentes. Certaines correspondent à l’entrée après encodage, d’autres aux représentations après l’attention, d’autres à ce qui sort des blocs MLP. Dans beaucoup de travaux d’interprétabilité, on parle aussi du residual stream, un flux vectoriel qui traverse les couches, auquel on ajoute successivement des contributions, couche après couche.
Pourquoi c’est important ? Parce que le modèle ne “décide” pas d’un coup. La réponse se construit progressivement dans cet espace de vecteurs. Une nuance de ton, une contrainte implicite, une direction argumentative, tout ça n’apparaît pas d’un seul bloc. Ça s’installe, ça se renforce, ça se combine, parfois ça se contredit, et à la fin, le texte sort comme la surface visible de toute cette cuisine interne.
Ces états intermédiaires, ce sont, grossièrement, les activations.
C’est ici que tout bascule.
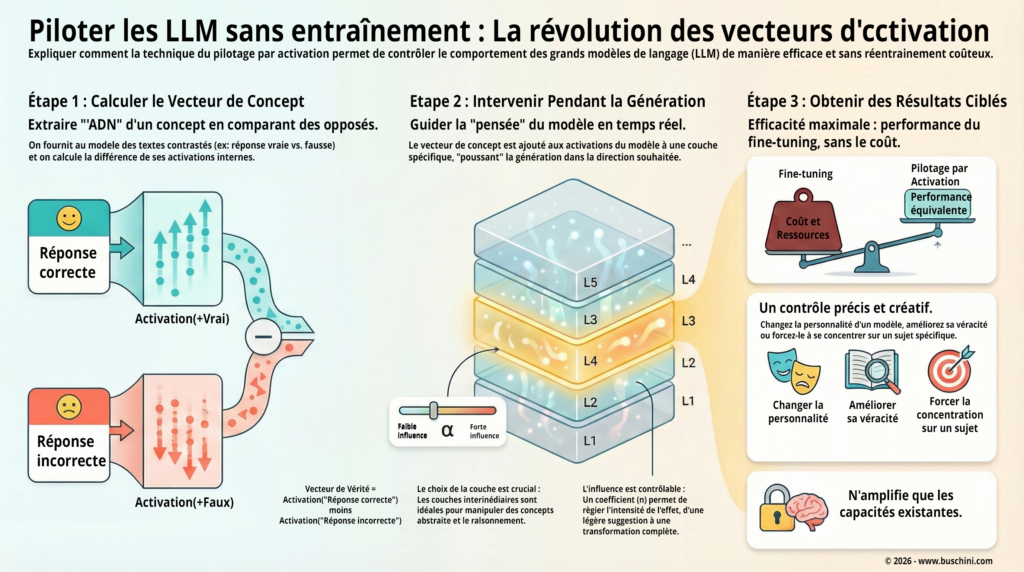
Si l’on peut observer, extraire, comparer des activations, alors on peut aussi, en principe, les modifier. Pas en changeant les poids du modèle, ce serait une autre catégorie d’intervention. Mais en ajoutant un petit signal, une “direction”, au bon endroit, au bon moment, pendant l’inférence. C’est exactement l’intuition derrière l’activation addition, où l’on ajoute un vecteur de pilotage aux activations pour orienter le comportement du modèle, sans optimisation et sans réentraîner les poids.
Il faut rester précis sur ce que cela implique. Modifier des activations, ce n’est pas injecter une règle logique dans le modèle. Ce n’est pas non plus lui donner une connaissance qu’il n’a pas. C’est plutôt augmenter la probabilité que le modèle emprunte une trajectoire interne plutôt qu’une autre, en amplifiant un certain “mode” de continuation déjà accessible.
Le steering, ou l’art d’intervenir pendant la pensée
Le steering regroupe plusieurs techniques, mais l’une des plus connues s’appelle activation addition, souvent abrégée ActAdd.
L’idée est assez simple, au moins dans son geste. On construit un vecteur, une direction dans l’espace interne du modèle, qui correspond à un comportement désiré, puis on ajoute ce vecteur aux activations pendant l’inférence. Dit autrement, on ne change pas le modèle, on change légèrement son état interne pendant qu’il calcule sa réponse.
La question évidente, c’est : comment obtient-on cette “direction” ?
Dans la version la plus classique décrite par Turner et al., on la fabrique par contraste. On choisit deux prompts très proches, sauf sur une dimension précise. Par exemple, une version “polie” et une version “agressive”, ou “positif” et “négatif”. On fait passer ces deux prompts dans le modèle, on regarde les activations à un endroit choisi (souvent dans le flux résiduel, couche par couche), puis on calcule une différence. Cette différence devient un vecteur de pilotage. L’intuition est que ce vecteur capture une partie de ce qui distingue les deux comportements.
Ensuite, on réutilise ce vecteur comme un petit gouvernail. On le rajoute aux activations pendant la génération, avec une intensité réglable. On peut en mettre très peu, juste pour nudger la sortie, ou trop, et dans ce cas le modèle se met à forcer le trait. C’est un point important à dire, parce que ça rappelle que le steering n’est pas une télécommande. C’est un biais, une poussée, pas une garantie.
Ce geste a deux intérêts.
D’abord, il est léger. On agit à l’exécution, sans optimisation supplémentaire et sans réentraîner tout le modèle. C’est l’un des arguments centraux d’ActAdd, le contrôle se fait au moment de l’inférence.
Ensuite, il est conceptuellement clair : on n’essaie pas de tout contrôler. On pousse légèrement le modèle dans une direction qu’il sait déjà emprunter, mais qu’il n’emprunte pas toujours spontanément, parce que, sans pilotage, il peut hésiter entre plusieurs continuations plausibles.
À ce stade, on pourrait croire que tout cela reste une forme de bricolage élégant, utile pour jouer sur le style, le ton, la “couleur” d’une réponse. Et pourtant, certains travaux récents vont plus loin, avec une idée voisine, mais un cran plus structurée : au lieu de seulement calculer ces directions, on peut les entraîner.
C’est ce que font Sinii et al. dans leur approche dite bias-only adaptation. Ils entraînent un vecteur par couche, tout en gardant les poids de base figés. Dans leur article, ils rapportent que, sur un modèle de 8 milliards de paramètres, cela représente environ 0,0016 % de paramètres supplémentaires.
Je garde ici une formulation prudente, parce que c’est important. Ce résultat est présenté par les auteurs dans un cadre expérimental précis, sur des tâches de raisonnement mathématique et des réglages donnés. On ne doit pas en faire une promesse générale, mais on peut en tirer une intuition robuste : il existe des leviers très petits, parfois minuscules, capables d’orienter des comportements déjà présents dans le modèle, sans avoir besoin de réentraîner l’ensemble.
Une scène simple pour comprendre l’intérêt, sans sur-vendre
Imaginez une chercheuse fictive, appelons-la Cerise. Elle n’utilise pas un llm pour “faire de la science à sa place”. Elle l’utilise comme on utiliserait un assistant très rapide, qui lit énormément, qui trie, qui résume, qui met en forme.
Son quotidien, c’est un flux continu : prépublications, articles, revues systématiques, compte rendus, fils de discussion entre équipes. Elle demande au modèle des synthèses courtes, des listes de points d’accord, des zones d’incertitude, des hypothèses à surveiller. Et la plupart du temps, ça marche. Le modèle est utile, parce qu’il transforme une montagne de texte en une carte lisible.
Le problème, c’est ce qui arrive de temps en temps, et qui est justement difficile à repérer quand on est pressé.
Le modèle relie deux résultats de manière trop assurée, alors que l’article original était plus prudent. Il résume une nuance comme si c’était une conclusion. Il comble une zone floue avec une phrase qui “sonne juste”, parce qu’elle ressemble à ce qu’on lit souvent dans ce domaine, mais sans que cette phrase soit réellement étayée par la source. Dans un contexte médical, ce glissement n’est pas anodin, parce qu’une formulation trop nette peut donner l’illusion qu’un point est établi alors qu’il est seulement plausible, discuté, ou dépendant du protocole.
Cerise ne cherche pas une ia plus “intelligente”. Elle cherche une ia plus rigoureuse dans sa manière de parler, plus consciente de ses propres limites, moins tentée par la phrase parfaite qui masque un trou.
Dans une logique de steering, l’idée n’est pas de fabriquer la rigueur à partir de rien. L’idée est plus modeste, et c’est justement pour ça qu’elle est intéressante : augmenter la probabilité que le modèle adopte un mode de sortie déjà accessible.
Par exemple, un mode où le modèle :
- Marque l’incertitude quand la source ne permet pas de trancher,
- Préfère “les données suggèrent” à “les données prouvent”,
- Signale qu’un résultat dépend d’une population, d’un critère d’inclusion, d’un effet de taille ou d’une méthode,
- Distingue plus clairement ce qui vient du texte source et ce qui ressemble à une extrapolation.
Concrètement, Cerise peut chercher à piloter non pas le contenu, mais la posture. Elle ne demande pas au modèle d’inventer moins, comme si on pouvait appuyer sur un bouton “vérité”. Elle cherche plutôt à le pousser vers une trajectoire interne qui produit, plus souvent, des sorties prudentes. Et même dans ce cas, elle garde une règle simple : ce qui compte, ce n’est pas que le modèle ait l’air sérieux, c’est que la sortie reste vérifiable.
Dit autrement : le pilotage ne crée pas la vérité. Il peut, dans certains cas, réduire la fréquence de formulations trop affirmatives, et orienter le modèle vers un style plus compatible avec un usage à risque. Mais il ne remplace ni les sources, ni la lecture, ni les garde-fous. C’est un réglage de comportement, pas une garantie épistémique.
Un exercice mental pour saisir la mécanique
Pas besoin de code pour saisir l’intuition. L’idée, c’est de comprendre le geste, pas de mémoriser une méthode.
Supposons que l’on veuille rendre un modèle plus “curieux” dans ses réponses. Pas plus savant, pas plus performant, juste plus enclin à ouvrir une piste, à poser une question, à relier le sujet à une cause, à une conséquence, à un “pourquoi”.
1) On collecte deux ensembles de formulations
On ne cherche pas des phrases parfaites. On cherche deux “modes” reconnaissables.
D’un côté, des formulations plates, qui ferment la discussion. Des phrases qui s’arrêtent net, comme si le sujet était clos.
Par exemple :
- « Le ciel est bleu. »
- « C’est comme ça. »
- « La réponse est X. »
De l’autre, des formulations qui ouvrent, qui questionnent, qui relancent. Pas du bavardage, plutôt un mouvement d’exploration.
Par exemple :
- « Le ciel est bleu, et la raison est intéressante. »
- « La réponse est X, mais ça dépend de Y. »
- « On peut aussi se demander ce qui se passe dans le cas limite. »
À ce stade, tu peux déjà sentir ce qu’on cherche à isoler : une posture, une manière d’embrayer, un réflexe de relance.
2) On cherche une direction interne
Dans les approches de type activation addition, l’idée est d’aller regarder ce qui change à l’intérieur du modèle quand tu passes d’un mode à l’autre.
Concrètement, tu fais traiter au modèle des exemples du groupe “plat” et des exemples du groupe “curieux”. Tu récupères, à un endroit choisi (par exemple une couche donnée), les activations associées à ces entrées.
Puis tu compares.
Le geste le plus simple, c’est de prendre une différence moyenne : en gros, “ce qui sépare” le mode plat du mode curieux, dans l’espace interne où le modèle représente le contexte.
Ce n’est pas une preuve que tu as capturé “la curiosité” au sens philosophique. C’est plutôt une hypothèse opérationnelle : il existe une direction qui, quand on l’ajoute, rend plus probable l’apparition de certains marqueurs de curiosité dans la sortie. Cette idée est décrite et testée dans les travaux sur l’activation addition.
3) On applique une petite poussée
Une fois que tu as ce vecteur de pilotage, tu peux l’ajouter aux activations pendant que le modèle génère.
Sans pilotage : « Le ciel est bleu. »
Avec une petite poussée vers “curiosité” : « Le ciel est bleu, principalement à cause de la diffusion de la lumière dans l’atmosphère. Et ce qui est intéressant, c’est qu’un détail de physique suffit à colorer tout notre paysage. »
Ce point est important : on parle de petite poussée. Si tu pousses trop fort, tu risques d’obtenir une caricature. Le modèle peut se mettre à relancer pour relancer, à ajouter des “n’est-ce pas fascinant” partout, ou à produire une curiosité de façade. C’est d’ailleurs une bonne manière de garder les pieds sur terre : le pilotage n’est pas une baguette magique, c’est un réglage, et un réglage peut être mal réglé.
Ce n’est pas de la magie. C’est un biais directionnel appliqué à un processus en cours. On ne change pas la mémoire du modèle, on ne lui injecte pas un savoir neuf. On change légèrement la trajectoire de sa génération, comme on change légèrement la trajectoire d’une phrase en cours d’écriture.
Alternatives, limites, et pourquoi ça rate parfois
Le steering ne remplace pas le prompt engineering. Il ne remplace pas non plus le fine-tuning.
Ce sont trois outils différents, avec trois coûts différents, et trois types de contrôle, et c’est déjà une bonne grille de lecture : qui contrôle quoi, à quel prix, et avec quel niveau de réversibilité.
Le prompt engineering agit “par la parole”. On ne touche pas au modèle, on essaie de le conduire avec des consignes, des exemples, un format, un rôle. C’est rapide, c’est gratuit au sens où ça ne demande pas d’entraînement. Mais c’est aussi fragile, parce que tu négocies avec un système qui reste libre d’interpréter. Quand le contexte change un peu, le comportement peut bouger plus que prévu.
Le fine-tuning agit “par la matière”. Tu modifies le modèle, même si c’est parfois une petite partie (adaptateurs, fine-tuning partiel, etc.). En échange, tu obtiens généralement un comportement plus stable sur une tâche donnée. Mais tu payes en données, en calcul, en itérations, puis en maintenance. Et tu prends un risque classique : améliorer un couloir peut dégrader un autre couloir, ou t’éloigner d’une polyvalence initiale.
Le steering, lui, agit “pendant le mouvement”. Tu ne changes pas les poids. Tu ajustes l’état interne pendant l’inférence. C’est un contrôle plus léger, plus proche d’un réglage en temps réel que d’une reprogrammation.
C’est pour ça que le steering brille quand :
- on veut un réglage rapide et réversible, parce qu’il suffit d’arrêter d’appliquer le vecteur pour revenir au comportement de base,
- On veut explorer un comportement sans engager une phase d’entraînement lourde, typiquement pour tester une hypothèse de contrôle avant d’investir plus,
- On veut piloter un style, une prudence, un ton, un angle, sans “figer” le modèle dans une personnalité unique.
Dit autrement, c’est un outil très pratique pour des ajustements de surface qui ont quand même un impact profond sur l’usage : ce que le modèle ose affirmer, la manière dont il nuance, la façon dont il structure une réponse.
Mais il échoue, ou devient risqué, quand :
- On pousse trop fort et on déforme la production, on obtient du style, mais on perd l’utilité, voire la cohérence,
- On tente d’activer une compétence qui n’existe pas vraiment dans le modèle, le pilotage ne crée pas une capacité, il ne fait que favoriser un chemin déjà accessible,
- On croit piloter “la vérité”, alors qu’on pilote souvent une manière de parler, c’est un piège très courant, parce qu’un ton prudent peut donner une impression de rigueur, et un ton assuré peut donner une impression de maîtrise, sans que le fond suive.
Il y a aussi une limite plus subtile, et elle explique une bonne partie des échecs : le steering intervient dans un système qui reste hautement non linéaire. Une petite poussée peut avoir un effet très propre sur certaines entrées, et un effet inattendu sur d’autres. Le même vecteur appliqué au même endroit peut produire un bénéfice sur un style de question, et une dégradation sur un autre, parce que le contexte n’active pas les mêmes circuits internes. Dit simplement, tu ne pilotes pas un bouton, tu pilotes un trajet.
Sur la question du coût, le papier de Sinii et al. donne des chiffres parlants dans leur protocole. Ils comparent notamment un fine-tuning complet et un entraînement de vecteurs de steering (leur approche “bias-only adaptation”), et rapportent un ordre de grandeur de temps par étape très différent. Dans la formulation que tu utilises ici, l’exemple “5,32 s par étape contre 0,07 s sur Llama 3.1 8B” doit être compris comme un résultat rapporté dans une configuration donnée, pas comme un chiffre universel.
Attention à l’interprétation, et tu le dis déjà, c’est très bien : ces durées dépendent du matériel, du code, du batch, des choix d’implémentation, et même de détails comme la précision numérique. Mais elles illustrent bien le type de gain recherché : déplacer l’effort d’un réentraînement massif vers une adaptation minimale, qui se branche sur un modèle déjà compétent.
Et c’est là, à mon avis, que se situe le bon cadre mental : le steering est un excellent outil d’orientation, tant qu’on accepte qu’il ne remplace ni la vérification, ni la mesure, ni les garde-fous. Il donne une main sur la trajectoire, pas une garantie sur la destination.
Comprendre ce qu’on pilote, l’apport des saes
Il reste une question, plus profonde.
On peut agir sur les activations, très bien. Mais comprend-on ce que ces activations “contiennent” ?
Parce qu’en pratique, quand tu appliques un vecteur de pilotage, tu fais un geste qui marche parfois très bien, et parfois beaucoup moins. Or, tant que tu ne sais pas exactement ce que tu as touché, tu restes dans une logique de réglage empirique. Tu ajustes, tu observes, tu recommences. C’est utile, mais c’est difficile à fiabiliser dès qu’on sort des démos.
C’est là qu’arrivent les sparse autoencoders (saes), dans un courant qu’on appelle souvent l’interprétabilité mécaniste. L’objectif n’est pas de rendre le modèle “transparent” au sens naïf, comme si on pouvait lire une pensée interne comme on lit une phrase. L’objectif est plus concret : trouver de meilleurs “objets” d’analyse que le neurone isolé. Les chercheurs d’Anthropic défendent l’idée qu’un neurone pris seul est souvent un mauvais candidat, parce qu’il peut mélanger plusieurs concepts, ce qu’ils décrivent sous le terme de superposition. Ils proposent donc de travailler avec des unités apprises, qu’ils appellent features, obtenues par une forme de dictionary learning via des SAEs.
L’intuition est la suivante.
Un SAE prend un vecteur d’activations (par exemple, à un endroit précis du modèle) et apprend à le reconstruire à partir d’un ensemble de composantes internes. La contrainte “sparse”, c’est que, pour une entrée donnée, seules quelques composantes doivent s’activer fortement. Dit simplement, on cherche une décomposition où la plupart des “features” restent éteintes, et où quelques-unes s’allument nettement, ce qui rend l’ensemble plus interprétable.
Ce point est important, parce qu’il explique l’ambition réelle des SAEs : ils ne prétendent pas “expliquer le modèle” en entier. Ils essaient de fournir une représentation intermédiaire plus lisible, un alphabet de concepts internes, au moins partiellement séparés les uns des autres.
À partir de là, l’idée qui fait briller les yeux est assez naturelle.
Si tu peux identifier des features associées à certains motifs de sortie, prudence, agressivité, raisonnement étape par étape, références à une catégorie de contenu, alors tu peux imaginer un pilotage plus propre. Au lieu de pousser une direction empirique construite par différence moyenne, tu pourrais agir sur des features mieux caractérisées : en renforcer certaines, en atténuer d’autres, et mesurer ce que ça change. On passerait progressivement d’un pilotage au ressenti à un pilotage plus instrumenté.
Attention, il faut rester prudent sur le niveau de maturité.
Même dans les travaux qui montrent des résultats impressionnants, les auteurs parlent d’outils de recherche et d’analyses sur des modèles ou des emplacements précis, pas d’un tableau de bord universel prêt à brancher partout. Et une difficulté reste centrale : une feature “interprétable” n’est pas automatiquement une feature “contrôlable” sans effets secondaires. Il existe aujourd’hui des travaux qui se concentrent justement sur la sensibilité des features apprises et sur les risques de mauvaise généralisation quand on intervient.
Donc oui, les SAEs donnent une piste très sérieuse : comprendre mieux ce qu’on touche quand on touche une activation, et relier le steering à une cartographie interne plus stable. Mais il faut garder la bonne posture : c’est une direction active, prometteuse, encore en construction, avec des succès réels, et des questions ouvertes sur la robustesse, la généralisation, et la sécurité des interventions.
Le miroir numérique
Ce que le steering change, au fond, ce n’est pas seulement une technique.
C’est une relation.
Jusqu’ici, la plupart des usages des llm ressemblaient à une conversation. On pose une question, on affine une consigne, on reformule, on insiste. On apprend à mieux parler au modèle, en espérant qu’il nous réponde mieux. Le contrôle passe par le langage.
Avec le steering, on entre dans une autre zone. On ne se contente plus d’interroger, on commence à régler. Parfois très finement, parfois en temps réel. On ne cherche plus seulement une réponse, on cherche une posture de réponse. Un mode de prudence. Une manière d’argumenter. Une tonalité. Un style de raisonnement. Et ce déplacement, même s’il reste technique, a quelque chose de psychologique.
Parce qu’à partir du moment où l’on sait qu’un modèle peut être poussé dans une direction interne plutôt qu’une autre, on cesse de le voir comme un simple “moteur à texte”. On commence à le voir comme un système qui possède plusieurs voies possibles, plusieurs manières d’aboutir, et que ces manières peuvent être favorisées. Ce n’est pas une preuve d’intention. Ce n’est pas une preuve de compréhension au sens humain. Mais c’est un fait pratique : le comportement visible dépend de trajectoires internes, et ces trajectoires peuvent être infléchies.
Et ce qui est troublant, c’est le retour réflexif.
À force de parler d’activations, de directions, de biais internes, on se surprend à regarder notre propre esprit avec des mots voisins. Pas parce que cerveau et llm seraient identiques, ils ne le sont pas, mais parce que la comparaison force une clarification.
Un llm ne pense pas “avec des phrases”. Il manipule des états internes qui évoluent, puis il produit du texte comme résultat final. Et nous, si on est honnête, on fait souvent l’inverse. On croit que nos pensées sont des phrases parce que c’est ce que notre conscience attrape le mieux, la phrase intérieure, la petite narration que l’on se raconte. Mais la phrase est souvent le dernier étage. En dessous, il y a des tendances, des émotions, des associations, des heuristiques, des élans, des résistances. Un état, avant le discours.
Le steering rend cette idée difficile à éviter : le texte n’est pas la pensée, c’est une sortie. Même chez nous. Le texte est parfois la façade propre d’un état beaucoup plus mouvant. Et quand on voit un modèle produire une phrase très assurée alors que le contenu peut être fragile, on comprend à quel point nous aussi pouvons confondre la qualité d’une formulation avec la solidité d’une idée.
Il faut rester net sur les limites.
Le steering n’explique pas la conscience. Il ne prouve rien sur l’humain. Il ne dit pas que “penser” se résume à des vecteurs. Il dit seulement, et c’est déjà beaucoup, qu’un système peut produire des sorties très différentes selon la manière dont son état interne est orienté.
Et à partir de là, une question s’impose, sans qu’on l’ait invitée.
Quand nous “changeons d’avis”, qu’est-ce qui change, exactement ? La phrase que l’on prononce, ou l’équilibre interne qui rend cette phrase possible ? Et si cet équilibre bouge, sous l’effet d’une expérience, d’une émotion, d’une conversation, d’un détail, alors peut-être que la liberté n’est pas un interrupteur, mais une dynamique. Une trajectoire, elle aussi, influençable, orientable, fragile.
Références
Pour les esprits méticuleux, amateurs de chiffres et de nuits blanches à vérifier les sources, voici les liens qui ont nourri cet article. Ils rappellent une chose simple : l’information existe encore, pour peu qu’on prenne le temps de la lire, de la comparer et de la comprendre. Mais dans un avenir proche, ce simple geste deviendra peut-être un luxe, car à mesure que les textes générés intégralement par des IA se multiplient, le vrai risque n’est plus la désinformation, mais la dilution du réel dans un océan de contenus simplement plausibles.
- Sinii, V. et al. (2025). Steering LLM Reasoning Through Bias-Only Adaptation. arXiv:2505.18706v3.
- Turner, A. et al. (2023). Activation Addition: Steering LMs without Optimization.
- Bricken, T. et al. (2023). Towards Monosemanticity: Decomposing Language Models With Dictionaries.
- Hubinger, C. (2024). A Toy Model of Steering.
- Olah, C. et al. (2020). An Overview of Early Vision in InceptionV1.