
Manifold-Constrained Hyper-Connections (mHC)
Note : Cerise et Oscar n’existent pas. Ce sont des personnages que j’ai créés pour rendre ce sujet plus concret, plus vivant. Si vous êtes expert en IA ou en psychologie cognitive, vous trouverez peut-être certaines simplifications frustrantes. C’est le prix à payer pour parler à un public large. Les références sont là pour ceux qui veulent creuser.
« Dis, Oscar, comment une intelligence artificielle apprend-elle à penser ?«
Cerise, assise en tailleur sur le tapis, regardait la pluie tracer des sillons sur la vitre. Oscar, plongé dans la lecture d’un article scientifique, leva les yeux. « C’est une grande question, Cerise. Imagine que tu construis une tour avec des legos. Chaque lego est une petite connaissance. Pour construire une tour très haute, très intelligente, il faut empiler des milliers, des millions de ces legos.«
« Facile ! » dit-elle.
« Pas si vite, » sourit Oscar. « Plus la tour est haute, plus elle devient fragile. Le moindre courant d’air peut la faire s’effondrer. C’est le grand secret et le grand problème des créateurs d’IA. Ils sont dans une course folle pour bâtir des tours de plus en plus hautes, mais ils se heurtent sans cesse à ce mur : l’instabilité.«
Cette course à la puissance, c’est celle des grands modèles de langage (LLM). Mais elle atteint aujourd’hui ses limites. Un mal mystérieux, des « pics de perte » soudains, fait dérailler des mois d’entraînement et gaspiller des fortunes en calcul. C’est dans ce contexte qu’une société nommée DeepSeek a proposé une solution. Une idée à l’élégance rare, cachée derrière un nom qui semble tout droit sorti d’un manuel de science-fiction : les Manifold-Constrained Hyper-Connections (mHC). Ce n’est pas juste une amélioration ; c’est une refonte philosophique de la manière dont l’information circule au cœur d’une IA.
Le Transformer et la mécanique de l’Attention
Avant de plonger dans les détails de l’innovation de DeepSeek, il faut comprendre la nature de la « machine » que nous cherchons à améliorer : le Transformer. Introduite en 2017 par des chercheurs de Google dans le papier révolutionnaire « Attention Is All You Need », cette architecture a changé la face de l’IA.
« Un Transformer, c’est le cerveau de l’IA, c’est ça ? » demanda Cerise.
« Exactement. Et son super-pouvoir, c’est le mécanisme d’attention, » répondit Oscar. « Avant les Transformers, les modèles lisaient une phrase mot par mot, de manière séquentielle, comme nous. C’était lent et ils avaient tendance à oublier le début de la phrase lorsqu’ils arrivaient à la fin. Le Transformer, lui, peut regarder tous les mots d’une phrase en même temps.«
Le mécanisme d’attention permet au modèle, pour chaque mot, de « peser » l’importance de tous les autres mots de la phrase. Par exemple, dans la phrase « Le chat a bu le lait car il avait soif », quand le modèle analyse le mot « il », le mécanisme d’attention va lui permettre de comprendre que « il » se réfère au « chat » et non au « lait ». Il crée des connexions dynamiques entre les mots, quelle que soit leur distance. C’est cette capacité à créer des liens contextuels à longue portée qui a rendu les Transformers si puissants. L’architecture de base d’un Transformer est une pile de ces couches d’attention, un peu comme les étages de notre tour de legos.
Paradoxe de la profondeur et révolution ResNet
Maintenant, comment empiler ces couches d’attention de manière stable ? Pour cela, il faut remonter à 2015 et à un paradoxe qui déconcertait les chercheurs en vision par ordinateur. La théorie suggérait qu’un réseau plus profond devrait être plus performant. Pourtant, en pratique, c’était l’inverse. Au-delà d’un certain nombre de couches, un réseau profond obtenait de moins bons résultats qu’un réseau moins profond. C’est ce que le papier « Deep Residual Learning for Image Recognition » nomme le problème de la dégradation.
« Attends, Oscar, » l’interrompit Cerise. « C’est comme si en ajoutant des étages à ma tour de legos, elle devenait non seulement plus fragile, mais aussi plus petite ? C’est absurde !«
« C’est exactement le paradoxe, » confirma Oscar. « L’explication est que l’optimiseur (l’algorithme d’entraînement) était incapable de trouver le bon chemin à travers ce labyrinthe de couches. La solution de Kaiming He et son équipe fut la connexion résiduelle (ResNet). L’idée est d’une simplicité désarmante : créer une « bretelle d’autoroute » qui permet au signal d’entrée de « sauter » par-dessus une couche et d’être ajouté directement à la sortie.«
Cette connexion « raccourci » garantit une propriété fondamentale : l’identity mapping. Elle assure que, dans le pire des cas, si une couche supplémentaire n’apporte rien, l’optimiseur peut simplement apprendre à l’ignorer et laisser passer le signal intact. Cette idée a été intégrée au cœur des Transformers, devenant la colonne vertébrale qui permet d’empiler leurs couches d’attention.
Goulot d’étranglement résiduel et échec des Hyper-Connexions
Cependant, en adaptant ce principe, le Transformer a conservé son talon d’Achille : le « residual stream » est resté une autoroute à voie unique. Toutes les informations sont compressées et forcées de circuler dans ce même et unique canal, créant un goulot d’étranglement.
La solution la plus intuitive était d’élargir l’autoroute. C’est le principe des Hyper-Connections (HC), explorées notamment par ByteDance : créer plusieurs flux d’information parallèles. Mais cette liberté a eu un coût terrible. En créant cet échangeur à voies multiples sans garde-fous, les architectes ont brisé la règle d’or de l’identité de projection.
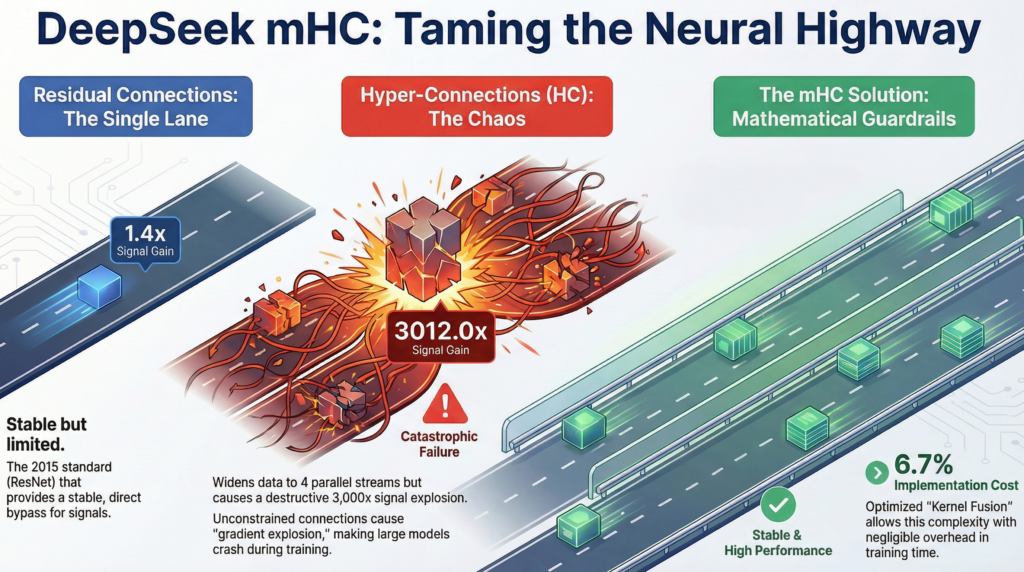
Le papier de DeepSeek sur mHC quantifie ce chaos avec une précision effrayante : le gain du signal peut atteindre des pics de près de 3000 à travers les couches. Cet emballement est un phénomène d’interférence constructive non contrôlée. Numériquement, cela se traduit par une « explosion des gradients » : les valeurs calculées deviennent si grandes qu’elles dépassent la capacité de représentation de l’ordinateur, et l’entraînement s’effondre.
Dompter le chaos grâce à la géométrie et l’ingénierie
Face à cet échec, l’équipe de DeepSeek a posé un diagnostic d’une grande justesse. Le problème n’était pas le nombre de voies, mais l’absence de règles claires pour organiser leur interaction. Multiplier les chemins sans cadre revenait à confondre richesse et désordre.
Imagine une grande place publique. Les gens peuvent s’y déplacer librement, changer de direction, se croiser, accélérer ou ralentir. Mais cette liberté n’existe que parce que la place a des bordures, des entrées et des sorties clairement définies. Sans ces limites, ce ne serait plus une place, mais un chaos sans forme.
C’est exactement ce type de liberté encadrée que l’équipe de DeepSeek a cherché à imposer aux flux d’information. Leur solution, baptisée Manifold-Constrained Hyper-Connections (mHC), consiste à restaurer une loi de conservation du signal en contraignant géométriquement la manière dont les flux peuvent se combiner.
La « cage » géométrique, le polytope de birkhoff Pour y parvenir, ils forcent les matrices qui gouvernent les échanges entre les flux à appartenir à une structure mathématique particulière, le polytope de Birkhoff.
« Un polytope ? Qu’est-ce que c’est que cette chose étrange ? » demanda Cerise, un peu inquiète.
« C’est moins intimidant qu’il n’y paraît« , la rassura Oscar. « Imagine un Rubik’s Cube. Tu peux le faire tourner dans tous les sens, mélanger les couleurs, explorer toutes les configurations possibles, mais le cube reste un cube. Il ne s’effondre pas, il ne se déforme pas. Le polytope de Birkhoff joue exactement ce rôle pour nos matrices de connexion. Il définit un espace de formes autorisées dans lequel elles peuvent évoluer, mais qu’elles ne peuvent jamais quitter.«
La règle pour rester dans cet espace est simple et extrêmement stricte. Les matrices doivent être doublement stochastiques, c’est-à-dire que la somme des valeurs de chaque ligne et de chaque colonne est toujours égale à un. Cette contrainte agit comme une véritable loi de conservation, empêchant toute amplification incontrôlée du signal.
Le « masseur » de matrices : l’algorithme de Sinkhorn-Knopp Mais comment forcer une matrice à entrer et à rester dans cette « cage » géométrique ? C’est là qu’intervient un algorithme de 1967 : Sinkhorn-Knopp.
« Imagine que ta matrice est une pâte à modeler difforme, » expliqua Oscar. « L’algorithme de Sinkhorn-Knopp est un « masseur » très patient. Il va d’abord « masser » toutes les lignes pour qu’elles aient la bonne taille. Mais en faisant ça, il a un peu déformé les colonnes. Alors, il va « masser » les colonnes. Mais ça a de nouveau un peu déformé les lignes… Il répète ce processus. Après seulement 20 « massages », la matrice est suffisamment proche de la forme idéale pour garantir la stabilité.«
Le défi de l’ingénierie : la fusion de kernels Avoir une belle équation ne suffit pas. Le défi majeur était de l’implémenter sans que le modèle devienne inutilisable. L’algorithme de Sinkhorn-Knopp, étant itératif, est un candidat parfait pour le « memory wall« . C’est là que le travail d’ingénierie de DeepSeek brille. Grâce à des techniques d’optimisation de bas niveau comme la fusion de kernels, ils ont regroupé de multiples opérations en une seule méga-instruction exécutée directement sur la puce. Le résultat est stupéfiant : cette architecture sophistiquée n’ajoute qu’un surcoût de calcul de seulement 6,7%.
Anatomie d’un changement de paradigme
À ce stade, quelque chose d’important s’est déplacé. On ne parle plus seulement d’un modèle plus stable ou plus performant, mais d’une autre manière de penser la construction même de l’intelligence artificielle.
La première conséquence est presque contre intuitive, elle remet en cause une croyance devenue dominante.
Les résultats publiés par DeepSeek montrent que l’amplification chaotique du signal, qui pouvait atteindre des facteurs vertigineux proches de 3000, est ramenée à un niveau stable d’environ 1,6. Cette stabilité retrouvée ne se contente pas d’éviter l’effondrement de l’entraînement, elle libère le potentiel réel du modèle. Les gains observés sur des tâches exigeantes de raisonnement sont significatifs, avec notamment une progression de 7,2 points sur le benchmark BBH et de 7,1 points sur le test de mathématiques GSM8K.
Ces chiffres racontent une histoire plus large. Ils montrent que la performance ne dépend plus uniquement de la taille brute du modèle ou de la quantité de calcul engagée. L’architecture devient une variable à part entière, capable de produire plus avec moins. C’est une remise en question directe des lois d’échelle telles qu’elles ont dominé la recherche ces dernières années.
La seconde implication touche à quelque chose de plus profond, la manière dont une IA organise son propre travail intérieur.
En stabilisant plusieurs flux parallèles d’information, le mHC ouvre la voie à une spécialisation fonctionnelle interne. Là où le flux résiduel unique obligeait toutes les informations à se mélanger dans un même canal, cette nouvelle structure permet d’imaginer une véritable division du travail. Un flux pourrait se concentrer sur la syntaxe, un autre sur les connaissances factuelles, un autre encore sur le raisonnement abstrait.
Cette hypothèse reste en partie exploratoire, mais elle est conceptuellement puissante. Elle rapproche l’architecture des modèles de certaines intuitions issues des sciences cognitives, où la spécialisation et la coordination des fonctions jouent un rôle central. L’intelligence ne naît pas seulement de l’accumulation, mais de l’organisation.
Enfin, cette innovation n’est pas seulement théorique. Elle a des effets très concrets sur le monde réel.
Dans un secteur où l’entraînement des modèles les plus avancés se chiffre en centaines de millions de dollars, une architecture capable d’améliorer les performances pour un surcoût de calcul limité à environ 6,7 % représente un avantage stratégique considérable. Elle réduit la dépendance à la force brute, abaisse les barrières économiques et peut redistribuer les cartes entre les acteurs capables d’innover sur la structure plutôt que sur la seule puissance de calcul.
Autrement dit, DeepSeek n’a pas seulement rendu les modèles plus solides. Ils ont déplacé le centre de gravité de la recherche, de la démesure vers la structure.
L’aube d’une révolution architecturale
« Donc, si je résume bien, » dit Cerise en se levant, « le Transformer est un super-cerveau qui regarde toute la phrase d’un coup. Pour le rendre plus puissant, on empile des couches, mais il faut des « bretelles d’autoroute » (ResNet) pour que ça ne s’effondre pas. Le problème, c’est que ça crée un bouchon. Alors, on a essayé de faire un grand échangeur (HC), mais c’était l’anarchie. Et DeepSeek a finalement réussi en inventant un code de la route (mHC) super strict pour que tout reste fluide et sécurisé.«
« C’est exactement ça, » conclut Oscar. « Le mHC n’est pas un remplacement du Transformer, mais une évolution de la manière dont ses couches sont connectées. Il garde la puissance des flux multiples tout en restaurant la stabilité des connexions classiques.«
L’innovation de DeepSeek est bien plus qu’une simple amélioration technique ; elle est la manifestation d’un changement de philosophie. Pendant près d’une décennie, la recherche en IA a été dominée par la « force brute », une course à la taille gouvernée par les lois d’échelle. Le mHC nous rappelle que la croissance a des limites physiques et que l’intelligence ne naît pas seulement de la taille, mais aussi de l’élégance de la structure.
En résolvant un problème fondamental de stabilité avec une solution mathématique issue des années 60 et une ingénierie logicielle de pointe, DeepSeek ne se contente pas de proposer une nouvelle brique de lego ; ils proposent un nouveau plan de construction pour toute la tour. C’est la preuve que l’avenir de l’IA ne se jouera pas uniquement dans les data centers surchauffés par des calculs toujours plus massifs, mais aussi dans la créativité des chercheurs et l’ingéniosité des architectes.
La question n’est peut-être plus de savoir jusqu’où nous pouvons empiler les briques, mais comment concevoir une tour qui tienne debout. Une tour où chaque brique sait pourquoi elle est là, où les forces se répartissent, et où la hauteur n’est plus un pari risqué, mais une conséquence naturelle de la structure.
L’ère de l’intelligence architecturale ne fait que commencer.
Références
Pour les esprits méticuleux, amateurs de chiffres et de nuits blanches à vérifier les sources, voici les liens qui ont nourri cet article. Ils rappellent une chose simple : l’information existe encore, pour peu qu’on prenne le temps de la lire, de la comparer et de la comprendre. Mais dans un avenir proche, ce simple geste deviendra peut-être un luxe, car à mesure que les textes générés intégralement par des IA se multiplient, le vrai risque n’est plus la désinformation, mais la dilution du réel dans un océan de contenus simplement plausibles.
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention Is All You Need. Advances in Neural Information Processing Systems 30 (NIPS 2017).
- Turner, R. E. (2024). An Introduction to Transformers. arXiv:2304.10557v5 [cs.LG].
- He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep Residual Learning for Image Recognition. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
- Xie, Z., Wei, Y., Cao, H., et al. (2026). mHC: Manifold-Constrained Hyper-Connections. arXiv:2512.24880v2 [cs.CL]. DeepSeek-AI.
- Zhu, D., Huang, H., Huang, Z., et al. (2024). Hyper-Connections. arXiv:2409.19606 [cs.LG].
- Sinkhorn, R., & Knopp, P. (1967). Concerning nonnegative matrices and doubly stochastic matrices. Pacific Journal of Mathematics, 21(2), 343-348.
- Espinosa Mena, J. R. (2024). On the Convergence of the Sinkhorn-Knopp Algorithm with Sparse Cost Matrices. arXiv:2405.20528v3 [math.OC].
- Baumeister, B., & Ladisch, F. (2017). A property of the Birkhoff polytope. arXiv:1610.02077v2 [math.CO].
- Hoffmann, J., Borgeaud, S., Mensch, A., et al. (2022). Training Compute-Optimal Large Language Models. Advances in Neural Information Processing Systems 35.