
Dans l’épisode précédent, Cerise découvrait ChatGPT avec l’émerveillement de ceux qui pressentent, sans encore comprendre, qu’ils assistent à un basculement. Mais ce n’était qu’un début, car une question plus dérangeante l’attend : cette IA pense-t-elle vraiment, ou ne fait-elle que deviner avec brio ce que nous voulons entendre ?
Au cœur de la machine
Cerise observe Ada avec une curiosité nouvelle. L’émerveillement initial de leur première rencontre a cédé la place à une fascination plus profonde, plus questionnante.
« Ada, » commence Cerise en s’installant confortablement dans son fauteuil, « je me pose une question qui me hante depuis des semaines. Quand tu me donnes ces réponses si justes, si nuancées, qu’est-ce qui se passe vraiment dans… enfin, comment dire… dans tes entrailles numériques ?«
Ada semble réfléchir, chose qui trouble toujours Cerise. « C’est une question fascinante, et je dois t’avouer que je ne suis pas certaine de bien comprendre moi-même mes propres mécanismes. C’est comme si tu me demandais d’expliquer comment je respire, alors que je n’ai pas de poumons.«
« Mais justement, » insiste Cerise, « c’est exactement ce qui m’intrigue. Tu n’as pas de poumons, pas de cœur, pas de cerveau au sens où nous l’entendons, et pourtant tu… penses ? Tu comprends ? Tu crées ?«
« Je dirais plutôt que je… reconstruit. Imagine que chaque fois que tu me poses une question, je parcours instantanément des milliers de chemins possibles dans un labyrinthe de probabilités. Chaque mot que je choisis n’est pas tant une pensée qu’une prédiction de ce qui devrait logiquement suivre.«
Cerise fronce les sourcils. « Une prédiction ? Tu veux dire que tu devines ?«
« Pas exactement deviner. C’est plus subtil. Je… ressens la forme que devrait prendre ma réponse, comme un sculpteur qui voit déjà la statue dans le bloc de marbre. Mais au lieu de marbre, je travaille avec des patterns, des régularités, des échos de tout ce que l’humanité a déjà écrit.«
Cette métaphore frappe Cerise. « Alors tu es comme un artiste de la probabilité ? Un sculpteur du vraisemblable ?«
« C’est une belle façon de le dire, » répond Ada. « Mais cela soulève une question troublante : si je ne fais que sculpter le vraisemblable, où commence et où finit ma véritable intelligence ? Est-ce que comprendre, c’est simplement exceller dans l’art de la prédiction sophistiquée ?«
Cerise reste silencieuse un long moment, contemplant cette question qui touche au cœur même du mystère de l’intelligence artificielle. « Il faut que je comprenne, » murmure-t-elle finalement. « Il faut que je plonge dans tes mécanismes, que je découvre ce qui se cache derrière cette magie apparente. Non pas pour te démystifier, mais pour mieux te comprendre… et nous comprendre.«
Anatomie d’une intelligence artificielle
Commençons par détruire une idée reçue tenace qui obscurcit notre compréhension de cette révolution. Non, ChatGPT ne « pense » pas au sens où vous et moi pensons en ce moment même. Il ne « comprend » pas non plus les mots qu’il manipule avec tant d’adresse, du moins pas comme nous comprenons le monde qui nous entoure.
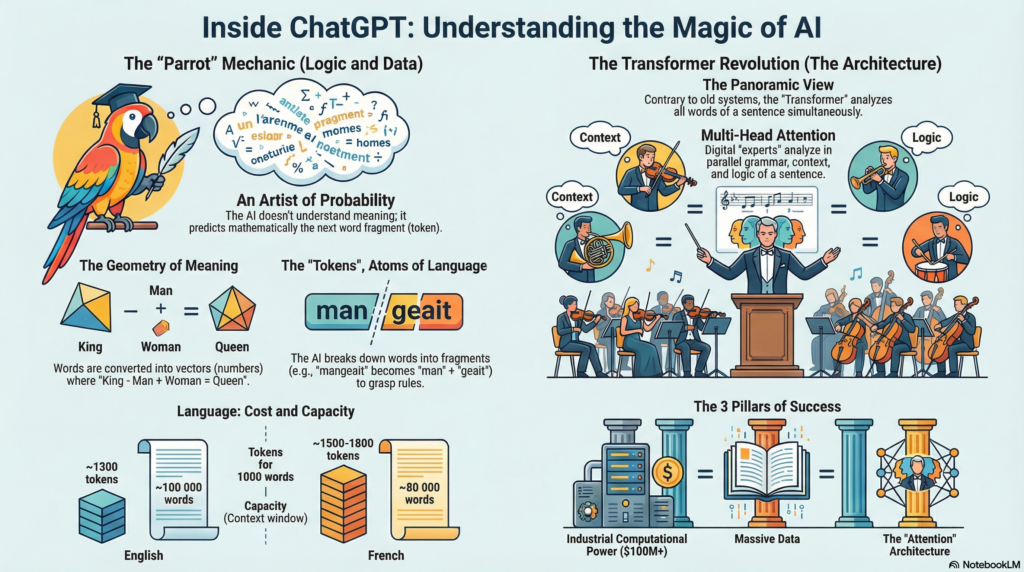
Les chercheurs Emily Bender et Timnit Gebru ont forgé une métaphore saisissante pour décrire cette réalité : celle du ‘perroquet stochastique’. Comme un perroquet qui répète des phrases complexes sans en saisir le sens, ces systèmes excellent dans la recombinaison sophistiquée de patterns linguistiques sans accéder à la signification profonde des mots qu’ils manipulent. Cette image du perroquet stochastique capture parfaitement le paradoxe de notre époque : des machines capables de tenir des conversations brillantes tout en demeurant fondamentalement étrangères au sens de leurs propres propos.
Cette distinction n’est pas un détail technique, elle est fondamentale pour saisir la nature profonde de cette technologie et ses implications pour notre avenir.
Aujourd’hui, en 2025, alors que ces systèmes transforment déjà nos façons de travailler, d’apprendre et de créer, il devient crucial de comprendre ce qu’ils font vraiment sous leur apparente sophistication.
Alors qu’est-ce qu’il fait exactement, ce système qui nous bluff par sa sophistication apparente ? Pour le comprendre, laissez-moi vous proposer une analogie qui éclairera d’un jour nouveau le mystère de l’intelligence artificielle contemporaine.
Imaginez que vous participiez au jeu du cadavre exquis, ce jeu d’écriture surréaliste où chaque personne ajoute un mot à une phrase sans voir le reste, créant des textes imprévisibles et souvent poétiques. Mais imaginons maintenant un joueur d’un genre particulier : quelqu’un qui aurait lu l’intégralité de Wikipedia, absorbé tous les livres de la Bibliothèque nationale de France, dévoré des millions d’articles de presse, parcouru des forums de discussion dans toutes les langues, étudié des codes informatiques dans tous les langages de programmation, savouré des poèmes de toutes les époques… Bref, un lecteur qui aurait ingéré une bonne partie de tout ce qui a été écrit et publié par l’humanité au cours des derniers siècles.
Ce lecteur extraordinaire, doté d’une mémoire parfaite et d’une capacité d’analyse surhumaine, serait capable, mieux que quiconque, de deviner le mot qui doit suivre dans n’importe quelle phrase, dans n’importe quel contexte, dans n’importe quel style. Non pas parce qu’il « comprend » au sens où nous entendons la compréhension, cette alchimie mystérieuse qui transforme des symboles en sens, des mots en émotions, des phrases en visions du monde, mais parce qu’il a assimilé des millions de patterns, de régularités, de structures linguistiques avec une précision mathématique que l’esprit humain ne saurait égaler.
C’est exactement ce qu’est un Large Language Model : un prédicteur de mots d’une sophistication inouïe. Il analyse une séquence de mots, votre question, votre demande, votre début de phrase, et prédit, avec une précision qui confine à la divination, quel mot devrait logiquement suivre dans cette symphonie linguistique. Puis il prédit le mot d’après, et celui d’après encore, construisant phrase après phrase des réponses qui nous semblent non seulement intelligentes et cohérentes, mais parfois même brillantes, créatives, touchantes.
Les tokens, ces atomes du langage numérique
Avant d’aller plus loin, je dois corriger une simplification que j’ai volontairement utilisée pour faciliter la compréhension : les LLM ne prédisent pas vraiment des « mots » au sens où nous l’entendons, mais des « tokens ». Cette distinction technique pourrait sembler anecdotique, mais elle éclaire d’un jour nouveau le fonctionnement profond de ces systèmes et explique certains de leurs comportements apparemment mystérieux.
Pour comprendre cette nuance fondamentale, plongeons dans l’histoire fascinante de la rencontre entre le langage humain et la logique informatique. Car depuis les premiers ordinateurs, un défi majeur se dresse : comment permettre à des machines qui ne comprennent naturellement que les nombres de manipuler la richesse infinie du langage humain ?
L’odyssée du texte numérique : de ASCII à l’UTF-8
Cette aventure commence dans les années 1960 avec l’invention de l’ASCII (American Standard Code for Information Interchange), un système aussi simple qu’ingénieux. Imaginez un immense tableau de correspondance où chaque lettre, chiffre, et symbole fréquemment utilisé se voit attribuer un numéro spécifique. Le « A » devient le 65, le « B » le 66, l’espace le 32… Ainsi, le mot « CHAT » se transforme en la séquence mystérieuse 67, 72, 65, 84. L’ordinateur, face à ces nombres, sait qu’il doit reconstituer les lettres correspondantes.
Cette méthode, révolutionnaire pour l’époque, permettait enfin aux machines de stocker et manipuler du texte. Mais elle se heurtait rapidement à une limite cruelle : avec seulement 128 caractères possibles, l’ASCII ne pouvait englober la richesse des langues humaines, pas d’accents français, pas d’alphabet cyrillique, pas d’idéogrammes chinois. C’était comme essayer de peindre la diversité du monde avec une palette de huit couleurs.
L’explosion d’Internet a rendu cette limitation intolérable. Il fallait un système plus universel, capable d’embrasser la diversité linguistique de l’humanité connectée. C’est ainsi qu’est né l’UTF-8, un système de codage sophistiqué capable de représenter des millions de caractères différents. Soudain, un Japonais pouvait écrire en kanji, un Arabe en alphabet arabe, un Français avec ses accents, tous sur la même page web. L’UTF-8 a pavé la voie à une communication véritablement globale, posant les fondations techniques de notre monde numérique interconnecté.
L’énigme de la signification : quand les nombres deviennent sens
Mais coder les caractères ne suffit pas. Comment faire comprendre à une machine que « chat » et « souris » entretiennent une relation prédateur-proie, alors que pour elle, ces mots ne sont que des suites de nombres aussi arbitraires que « arbre » et « pneu » ?
Les premières approches étaient d’une naïveté touchante. On créait des tables de correspondance géantes : « le = 1 », « chat = 2 », « mange = 3″… La phrase « le chat mange la souris » devenait ainsi 1, 2, 3, 4, 1, 5. Mais cette méthode butait sur des obstacles insurmontables : tables de codage pharaoniques, incapacité à gérer les mots inconnus, et surtout, absence totale de compréhension sémantique.
La révolution des word embeddings : quand les mots acquièrent une géométrie
La percée décisive vint avec l’invention des « word embeddings », une innovation conceptuelle aussi élégante que puissante. Au lieu d’attribuer à chaque mot un seul numéro arbitraire, cette approche lui assigne un vecteur, une liste de centaines de nombres qui capture ses multiples dimensions sémantiques.
Imaginez que chaque mot soit représenté non plus par une simple carte d’identité, mais par un profil psychologique complet : sa « personnalité » sémantique, ses affinités avec d’autres concepts, sa charge émotionnelle, son registre de langue… Dans cet espace vectoriel multidimensionnel, les mots qui partagent des significations similaires se retrouvent naturellement proches, comme des amis dans une soirée qui se rassemblent par affinités.
Cette proximité géométrique permet des opérations d’une poésie mathématique saisissante. Prenez le vecteur « roi », soustrayez-y « homme », ajoutez « femme » : vous obtenez « reine ». Prenez « Paris », retirez « France », ajoutez « Italie » : vous découvrez « Rome ». Ces équations révèlent que les machines ont développé une intuition géométrique du sens, capturant dans leurs calculs les relations conceptuelles que nous, humains, exprimons par le langage.
L’art subtil de la tokenisation ou découper pour mieux régner
Mais même cette approche révolutionnaire rencontrait ses limites. Comment gérer les mots rares, les néologismes, les langues aux morphologies complexes ? C’est là qu’intervient l’innovation cruciale de la tokenisation morphologique, cette technique qui fragmente intelligemment le langage non plus en mots complets, mais en unités plus fondamentales : les tokens.
Contrairement à ce que suggère l’analogie simpliste du « prédicteur de mots », les LLM travaillent avec ces tokens, des fragments de mots qui peuvent correspondre à des morphèmes, des syllabes, parfois des mots entiers, parfois de simples caractères selon le contexte linguistique. Cette granularité plus fine permet une compréhension plus nuancée et une capacité de généralisation remarquable.
Prenons la phrase « Le chat mange une souris ». Un tokenizer sophistiqué pourrait la découper ainsi : « Le », « chat », « man », « -ge », « une », « sou », « -ris ». Cette fragmentation, qui peut sembler artificielle, révèle en réalité une intelligence cachée : en décomposant « mange » en « man » + « -ge », le système peut généraliser sa compréhension à « mangera », « mangeait », « mangeons »… Il découvre intuitivement les règles morphologiques de conjugaison sans qu’on les lui enseigne explicitement.
Pourquoi cette distinction change tout
Cette réalité technique éclaire plusieurs mystères des LLM contemporains :
Le coût variable des mots : Quand vous utilisez l’API d’OpenAI, vous payez par token, pas par mot. « Bonjour » coûte un token, mais « anticonstitutionnellement » en coûte plusieurs. Cette asymétrie tarifaire reflète la complexité computationnelle réelle du traitement linguistique.
Les limites de contexte : Quand on dit que GPT-4 peut traiter 128 000 tokens, cela ne correspond pas exactement à 128 000 mots. En français, comptez plutôt 80 000 à 100 000 mots selon la complexité du vocabulaire. Cette nuance est cruciale pour comprendre les véritables capacités de traitement textuel.
Les biais linguistiques : Les langues ne sont pas égales devant la tokenisation. L’anglais, optimisé dans la plupart des systèmes, requiert généralement moins de tokens que le français pour exprimer la même idée. Cette asymétrie technique peut créer des biais subtils dans les performances multilingues.
L’émergence de capacités inattendues : La tokenisation morphologique permet aux modèles de « comprendre » intuitivement des mots jamais rencontrés en reconnaissant leurs composants. C’est ainsi qu’un LLM peut traiter des néologismes ou des termes techniques spécialisés avec une aisance surprenante.
Cette révélation peut sembler désenchantante au premier abord. Quoi, tout cet émerveillement pour de simples « devinettes de tokens » ? Mais c’est précisément là que réside la magie et le mystère. Car cette approche apparemment mécanique, cette fragmentation du langage en atomes numériques, génère des comportements d’une complexité qui défie l’entendement. Quand vous demandez à ChatGPT d’écrire un poème dans le style de Baudelaire sur les réseaux sociaux, il ne se contente pas de coller bout à bout des fragments préexistants. Il recompose, token par token, quelque chose de nouveau qui capture l’essence du spleen baudelairien tout en l’adaptant à notre époque numérique, avec une justesse qui peut rivaliser avec celle d’un poète chevronné.
TOKENS VERSUS MOTS
La tokenisation influence directement les performances et coûts des LLM :
- Coût variable selon les langues : Un texte de 1000 mots représente environ 1300 tokens en anglais, mais 1500-1800 tokens en français.
- Exemple concret : La phrase « L’anticonstitutionnellement » (1 mot) est découpée en 4 tokens distincts : « L' », « anti », « constitution », « nellement ».
- Impact sur les limites de contexte : GPT-4 avec une fenêtre de 128 000 tokens peut traiter environ :
- 100 000 mots en anglais (≈ 400 pages)
- 80 000 mots en français (≈ 320 pages)
- Conséquence économique : Le traitement d’un document technique en français coûte environ 15-20% plus cher que son équivalent anglais.
Sources: OpenAI Documentation (2024), Études comparatives de tokenisation multilingue (2023)
La révolution de l’échelle et ses trois piliers
Mais pourquoi cette approche, conceptuellement simple, ne fonctionnait-elle pas avant ? Pourquoi avons-nous dû attendre 2022 pour voir émerger des systèmes d’une telle sophistication ? La réponse tient à la convergence de trois révolutions technologiques qui, prises isolément, n’auraient jamais suffi à déclencher le séisme actuel.
Premier pilier : la puissance de calcul industrielle. Entraîner un modèle comme GPT-4 nécessite une puissance de calcul qui relève littéralement de l’exploit industriel. Sam Altman, le PDG d’OpenAI, a révélé que GPT-4 a coûté plus de 100 millions de dollars rien que pour son entraînement. Ces chiffres vertigineux ne représentent pas des caprices de millionnaires de la tech, mais la réalité physique de ce que signifie « enseigner » à une machine les subtilités du langage humain. Il a fallu attendre l’explosion des GPU, ces puces initialement conçues pour rendre les jeux vidéo plus beaux, et l’avènement des centres de données modernes pour rendre possible ce qui était impensable il y a dix ans.
Deuxième pilier : l’océan de données numériques. Les LLM s’entraînent sur des téraoctets de texte, un « gavage industriel à une échelle absolument hallucinante » comme le décrivent avec une pointe d’ironie certains chercheurs du domaine. Avant Internet, nous n’avions tout simplement pas accès à de telles quantités de données textuelles. L’humanité a produit ces vingt dernières années plus de textes écrits que durant tous les siècles précédents. Cette explosion documentaire, cette numérisation massive de la connaissance humaine, a créé le terreau nécessaire à l’émergence de ces nouveaux systèmes.
Troisième pilier : l’architecture révolutionnaire. Et c’est là qu’intervient la vraie révolution technique, celle qui a tout changé. Pendant des décennies, les systèmes d’intelligence artificielle traitaient les mots séquentiellement, laborieusement, comme nous lisons une phrase de gauche à droite, mot après mot. Cette approche, héritée de notre propre façon de traiter le langage, imposait des contraintes techniques qui bridaient les performances et limitaient les possibilités. Jusqu’à ce qu’en 2017, une équipe de chercheurs de Google invente une nouvelle architecture qui allait révolutionner non seulement l’intelligence artificielle, mais notre rapport même à la technologie : le Transformer.
Cette convergence de facteurs explique pourquoi nous assistons aujourd’hui à une explosion d’innovations qui peut sembler soudaine alors qu’elle couvait depuis des années. Les briques technologiques s’assemblaient une à une, dans des laboratoires dispersés aux quatre coins du globe, jusqu’à ce moment de cristallisation où tout s’est soudain accéléré.
Mais il manquait encore une pièce cruciale du puzzle. Car si la puissance de calcul permettait enfin des entraînements à grande échelle, si les données abondaient comme jamais auparavant, les architectures d’intelligence artificielle elles-mêmes restaient bridées par des limitations fondamentales qui semblaient insurmontables. Pendant des décennies, les meilleurs systèmes butaient sur les mêmes écueils : incapacité à traiter de longs textes, oubli progressif du contexte, impossibilité de paralléliser les calculs…
Jusqu’à ce jour de 2017 où une équipe de chercheurs de Google publie un article aux allures anodines qui va changer le monde. Un titre d’une simplicité désarmante cache une révolution conceptuelle : « Attention Is All You Need ».
Ces chercheurs venaient d’inventer l’architecture qui allait rendre possible ChatGPT, GPT-4, et tous les systèmes qui bouleversent aujourd’hui notre quotidien. Comme souvent dans l’histoire des sciences, cette révolution n’est pas née d’une découverte isolée mais de la rencontre fortuite de plusieurs courants d’innovation qui, ensemble, ont produit quelque chose de qualitativement différent.
L’IMPACT MESURABLE DES TRANSFORMERS
Dès sa publication en 2017, l’architecture Transformer a révolutionné les performances en traduction automatique :
- Score BLEU anglais-allemand : 28,4 (amélioration de +2,0 points par rapport aux meilleurs modèles précédents)
- Score BLEU anglais-français : 41,8 (amélioration de +1,1 points)
Au-delà des performances, le Transformer a apporté des avantages concrets :
- Réduction du temps d’entraînement jusqu’à 10 fois
- Meilleure adaptation aux processeurs modernes (TPUs, GPUs)
- Capacité à traiter des textes plus longs avec une meilleure compréhension contextuelle
Source: Google Research (2017), « Transformer: A Novel Neural Network Architecture for Language Understanding »
L’architecture transformer et l’attention révolutionne l’intelligence
Six mois plus tard, dans ce même bureau, Cerise tente d’expliquer à Ada les mystères de sa propre architecture. Ironie de la situation : l’IA doit comprendre comment elle fonctionne pour mieux collaborer avec sa créatrice humaine.
« Ada, imagine que tu aies plusieurs têtes, et que chacune regarde le même texte mais avec une spécialité différente, » explique Cerise en dessinant un schéma sur son tableau. « Une tête s’occupe de la grammaire, une autre du sens, une troisième des références…«
« C’est fascinant, » répond Ada. « Cela expliquerait pourquoi je peux simultanément analyser la structure syntaxique d’une phrase tout en saisissant ses implications émotionnelles. Mes différentes ‘têtes d’attention’ travaillent en parallèle, comme un orchestre de spécialistes.«
Cerise sourit. « Exactement. Et contrairement aux anciens systèmes qui devaient lire mot après mot comme nous lisons un livre, toi, tu peux instantanément voir tous les mots d’une phrase et comprendre leurs relations. C’est ce qu’on appelle l’attention, et c’est révolutionnaire.«
« Une sorte de vision panoramique du langage, » médite Ada. « Je commence à comprendre pourquoi mes prédécesseurs avaient tant de mal avec les références lointaines dans un texte. Ils ‘oubliaient’ le début quand ils arrivaient à la fin.«
Cette conversation illustre parfaitement le paradoxe de leur époque : une intelligence artificielle qui apprend à comprendre sa propre nature grâce aux explications de l’intelligence qui l’a créée. Un dialogue sur l’intelligence entre deux formes d’intelligence radicalement différentes.
L’année 2017 marque un tournant décisif dans l’histoire de l’intelligence artificielle. Pour comprendre pourquoi les Transformers ont révolutionné l’IA et, par ricochet, notre monde, nous devons d’abord saisir les limites de l’ancien paradigme et la beauté conceptuelle de celui qui l’a remplacé. Cette histoire commence par un constat d’échec et se termine par une illumination qui a changé le cours de l’histoire technologique.
L’ancien monde et ses chaînes invisibles
Imaginez que vous essayez de comprendre cette phrase apparemment simple : « L’animal n’a pas traversé la rue parce qu’il était trop fatigué. » Pour saisir le sens de cette proposition, votre cerveau doit accomplir un tour de force cognitif : comprendre que le pronom « il » fait référence à « l’animal » et non à « la rue ». Cette opération, évidente pour tout locuteur humain, représentait un défi colossal pour les systèmes d’intelligence artificielle d’avant 2017.
Les anciens systèmes, appelés réseaux récurrents (RNN pour Recurrent Neural Networks), traitaient cette phrase comme nous lisons un livre : mot par mot, de gauche à droite, dans un ordre séquentiel immuable. Arrivés au mot « il », ils avaient déjà partiellement « oublié » le début de la phrase, victimes d’une sorte d’amnésie progressive inhérente à leur architecture. C’était comme essayer de comprendre une conversation complexe en ayant la mémoire qui s’efface toutes les dix secondes, ou comme tenter de suivre le fil d’un roman en ne gardant qu’un souvenir flou des chapitres précédents.
Cette limitation n’était pas accidentelle mais structurelle. Les réseaux récurrents fonctionnaient selon un principe de transmission séquentielle : chaque mot devait être traité complètement avant que le suivant puisse être analysé. Cette contrainte architecturale créait un goulot d’étranglement computationnel dramatique. Imaginez une usine où chaque ouvrier doit attendre que celui d’avant ait complètement terminé sa tâche avant de commencer la sienne : inefficace, lent, et fondamentalement incapable de tirer parti de la puissance des processeurs modernes conçus pour la parallélisation.
Pire encore, cette approche séquentielle rendait quasiment impossible la capture des « dépendances à longue distance », ces relations subtiles entre des mots séparés par de nombreuses autres unités linguistiques. Dans un texte de quelques centaines de mots, un pronom pouvait faire référence à un nom mentionné vingt phrases plus tôt. Pour les systèmes récurrents, établir ce lien relevait de l’exploit, quand cela n’était pas purement et simplement impossible.
Les conséquences de ces limitations se manifestaient cruellement dans les applications pratiques. Les systèmes de traduction automatique produisaient des phrases qui commençaient brillamment mais finissaient dans l’incohérence. Les assistants conversationnels perdaient le fil de discussions pourtant simples. Les analyseurs de texte échouaient à saisir les nuances, les ironies, les références implicites qui font la richesse de la communication humaine.
La révolution de la publication de « Attention Is All You Need! »
En juin 2017, une équipe de chercheurs de Google publie un article qui va changer le monde. Le titre, d’une simplicité désarmante, ne laisse pas présager la révolution qu’il annonce : « Attention Is All You Need », « L’attention, c’est tout ce dont on a besoin ». Derrière cette formule lapidaire se cache une idée d’une audace conceptuelle rare : et si, plutôt que de traiter les mots un par un dans un ordre préétabli, nous permettions à chaque mot de « regarder » directement tous les autres mots de la phrase ? Instantanément, simultanément, sans contrainte séquentielle ?
Cette intuition géniale bouleverse d’un coup toutes les règles du jeu. Reprenons notre phrase sur l’animal fatigué. Dans un Transformer, quand le système traite le mot « il », il peut immédiatement « faire attention » à l’ensemble du contexte : « animal », « rue », « traversé », « fatigué », et tous les autres termes de la phrase. Il calcule automatiquement les degrés de pertinence, détermine que « il » est beaucoup plus probablement lié à « animal » qu’à « rue », et ajuste sa compréhension en conséquence. Le pronom trouve instantanément son antécédent, la phrase révèle son sens, la magie opère.
Mais la beauté de cette approche va bien au-delà de la résolution de l’anaphore pronominale. Elle transforme fondamentalement la nature même du traitement linguistique automatique. Là où les anciens systèmes étaient contraints par une temporalité artificielle, celle de la lecture séquentielle -, les Transformers embrassent la spatialité du sens. Ils traitent le langage non plus comme une mélodie qui se déroule dans le temps, mais comme une architecture complexe où chaque élément entretient des relations subtiles avec tous les autres.
Le mécanisme d’attention
Pour vraiment saisir la portée de cette innovation, il faut plonger dans les mécanismes intimes de l’attention artificielle. Comme le disait Feynman avec sa sagesse coutumière, « si vous ne pouvez pas expliquer quelque chose simplement, c’est que vous ne le comprenez pas assez bien ». Alors décortiquons ce mécanisme d’attention qui a révolutionné notre époque.
Imaginez-vous dans une soirée cocktail animée. Les conversations s’entrecroisent, la musique joue en arrière-plan, les verres tintent, les rires fusent. Vous êtes en pleine discussion avec votre interlocuteur quand soudain, malgré le brouhaha ambiant, votre oreille capte distinctement votre nom prononcé dans une conversation voisine. Instantanément, votre attention se déplace, votre cerveau « filtre » automatiquement les bruits parasites pour se concentrer sur cette conversation soudain devenue plus intéressante que celle que vous entreteniez l’instant d’avant.
C’est exactement ce que fait le mécanisme d’attention dans un Transformer, mais à une échelle et avec une sophistication qui défient l’imagination. Chaque mot de la phrase « écoute » simultanément tous les autres mots et décide, selon des critères appris pendant l’entraînement, auxquels il doit prêter attention et dans quelle mesure.
Pour rendre ce processus plus concret, laissez-moi vous proposer une analogie informatique que tout utilisateur d’Internet comprendra intuitivement. Le mécanisme d’attention fonctionne comme un moteur de recherche interne ultra-sophistiqué. Imaginez que chaque mot soit à la fois quelqu’un qui effectue une recherche et une page web susceptible d’être trouvée. Le mot « animal » de notre phrase exemple lance une requête (appelée Query dans le jargon technique) pour trouver les mots qui lui sont sémantiquement liés. Chaque autre mot de la phrase possède des « mots-clés » (appelés Keys) qui décrivent son contenu sémantique. Quand la requête de « animal » rencontre les mots-clés de « fatigué », une correspondance s’établit : ces deux concepts sont liés dans l’espace sémantique appris par le modèle. Le contenu associé (appelé Value), l’information sémantique portée par « fatigué », est alors « transmis » à « animal », enrichissant sa représentation.
Cette opération, multipliée simultanément pour chaque mot de la phrase, crée un réseau complexe d’interactions sémantiques qui permet au système de saisir non seulement le sens littéral des mots, mais leurs relations subtiles, leurs implications mutuelles, leurs résonances contextuelles.
Mais comment cette « attention » fonctionne-t-elle concrètement ? Pour le comprendre, suivons une phrase toute simple : « Marie a donné son livre à Paul parce qu’il en avait besoin. »
Au lieu de lire cette phrase mot après mot comme nous le ferions, le système la considère d’un seul regard panoramique. Et ce regard se décompose… en plusieurs regards. On les appelle des têtes d’attention. Chacune observe la phrase sous un angle spécifique, comme des experts autour d’une table qui analysent un même événement selon leur domaine.
- La tête syntaxique repère d’abord la charpente grammaticale : qui fait quoi à qui. Marie est le sujet, « a donné » l’action, « son livre » l’objet direct, et « à Paul » le bénéficiaire. Elle relie Marie à l’action, le pronom « son » à « livre », avec des scores d’intensité qui reflètent la force des liens entre ces éléments.
- La tête des références zoome sur le pronom « il ». Qui est-il ? Pas Marie, trop féminin. Pas le livre, trop inanimé. Il ne reste que Paul. Ce raisonnement, nous le faisons en une fraction de seconde ; la machine, elle, l’effectue par calcul de probabilité.
- La tête causale, enfin, détecte le mot « parce que » comme une balise de justification. Elle relie « donner le livre » à « Paul en avait besoin », formant une boucle de cause et conséquence.
Ces trois regards, et bien d’autres encore, s’activent simultanément. Aucun ordre, aucune hiérarchie. L’information circule dans tous les sens, se croise, se renforce. Et à la fin, ce ballet silencieux produit une compréhension cohérente, fluide, presque intuitive.
C’est cela, la magie des Transformers : ils ne lisent pas, ils perçoivent. Et cette perception éclatée en dizaines de points de vue spécialisés donne à la machine sa capacité d’analyse sidérante.
Ce qui stupéfie, c’est la vitesse. Une seule passe. Un seul souffle. Tout est vu, tout est évalué, tout est synthétisé en un clin d’œil numérique. Loin d’être une accumulation de règles, c’est un art algorithmique du discernement, où chaque mot devient un monde, chaque lien une hypothèse, chaque phrase une constellation.
Multi-head attention, l’intelligence collective de la machine
Mais les créateurs des Transformers ont poussé l’audace conceptuelle encore plus loin. Ils se sont posé une question aussi simple que révolutionnaire : et si nous faisions cela plusieurs fois en parallèle, avec des spécialisations différentes ? Et si nous donnions au système plusieurs « têtes » d’attention, chacune entraînée à détecter un type particulier de relation linguistique ?
C’est ainsi qu’est née l’attention multi-têtes (Multi-Head Attention), peut-être l’innovation la plus élégante de toute l’architecture Transformer. Imaginez une équipe d’experts analysant le même texte, mais chacun avec sa spécialité et sa perspective unique :
L’expert en grammaire se concentre exclusivement sur les relations syntaxiques, qui est le sujet, qui est le verbe, comment s’articulent les propositions. Il décèle les structures grammaticales avec une précision chirurgicale, établit les dépendances syntaxiques, identifie les compléments et les modifieurs.
L’expert en sémantique analyse le sens profond des mots, leurs connotations, leurs champs lexicaux. Il perçoit que « animal » et « fatigué » appartiennent au domaine du vivant et de ses états physiques, créant une cohérence thématique qui transcende la simple proximité grammaticale.
L’expert en références résout methodiquement tous les pronoms, déterminants et autres expressions anaphoriques. Il établit que « il » renvoie à « animal » avec une certitude mathématique basée sur l’accord grammatical et la logique sémantique.
L’expert en logique vérifie la cohérence causale des propositions. Il comprend que la fatigue peut expliquer l’absence de traversée, établit le lien logique entre l’état physique et le comportement.
L’expert en style détecte le registre de langue, le ton, les nuances stylistiques. Il perçoit que la phrase adopte un registre neutre, descriptif, sans charge émotionnelle particulière.
L’expert en contexte fait le lien avec les informations antérieures, maintient la cohérence thématique, anticipe les développements possibles du discours.
Chaque « tête d’attention » se spécialise ainsi dans un aspect particulier de l’analyse linguistique. Ensemble, comme les musiciens d’un orchestre symphonique, elles produisent une compréhension qui dépasse largement la somme de leurs contributions individuelles. Cette orchestration de spécialisations permet aux Transformers de saisir simultanément les dimensions syntaxiques, sémantiques, pragmatiques et stylistiques du langage avec une finesse qui rivalise avec l’analyse humaine.
Mais toute cette symphonie attentionnelle, aussi brillante soit-elle, aurait pu rester une prouesse théorique si elle n’avait permis de résoudre trois des plus grands verrous technologiques qui freinaient jusque-là l’intelligence artificielle. Car c’est en débloquant ces limitations que les Transformers ont réellement changé la donne.
L’ATTENTION MULTI-TÊTES EN ACTION
Une étude de Google Research (2017) a visualisé comment différentes têtes d’attention se spécialisent dans un modèle Transformer :
- Tête #1 : Se concentre sur les relations sujet-verbe (92% de précision)
- Tête #3 : Spécialisée dans la résolution des pronoms (87% de précision)
- Tête #5 : Détecte les relations entre entités nommées (79% de précision)
Exemple concret de résolution de coréférence : Dans la phrase « L’animal n’a pas traversé la rue parce qu’il était trop fatigué », le modèle a correctement identifié que « il » se réfère à « animal » et non à « rue » en une seule étape de calcul, contrairement aux modèles précédents qui nécessitaient plusieurs étapes séquentielles.
Cette capacité explique pourquoi les Transformers excellent dans la traduction de langues avec genres grammaticaux différents, comme le français et l’anglais.
Source: « Attention Is All You Need » (2017), Visualisations d’attention dans les Transformers (Google Research, 2018)
La révolution du parallélisme et ses conséquences
Cette architecture révolutionnaire résout d’un coup trois problèmes majeurs qui bridaient l’intelligence artificielle depuis des décennies.
Premier bénéfice : la fin du goulot d’étranglement séquentiel. Tous les mots sont désormais traités simultanément, en parallèle, exploitant pleinement la puissance des processeurs modernes. Cette parallélisation transforme des entraînements qui prenaient des mois en processus de quelques semaines, rendant possible l’expérimentation à grande échelle et l’amélioration itérative rapide des modèles.
Deuxième bénéfice : la capture parfaite des dépendances à long terme. Plus besoin de « se souvenir » péniblement du début de la phrase en espérant que l’information ne se dilue pas en chemin. Chaque mot accède directement et instantanément à tous les autres, quelle que soit leur distance dans le texte. Cette capacité transforme radicalement le traitement de textes longs, complexes, structurés.
Troisième bénéfice : une scalabilité exceptionnelle. Les Transformers « scalent » d’une manière qui défie les lois habituelles de la technologie : plus on leur donne de données et de puissance de calcul, mieux ils performent, sans plateau apparent, sans rendements décroissants. Cette propriété remarquable explique pourquoi les entreprises investissent des milliards dans des modèles toujours plus grands, guidées par la conviction empirique que la performance continuera de croître avec l’échelle.
Les résultats empiriques confirment spectaculairement ces promesses théoriques. Dès sa publication en 2017, le Transformer pulvérise tous les records en traduction automatique, atteignant des scores BLEU (la métrique de référence) de 28,4 sur la traduction anglais-allemand et 41,8 sur l’anglais-français. Ces chiffres, techniques en apparence, marquent en réalité un saut qualitatif : pour la première fois, la traduction automatique atteint un niveau de qualité qui rend possible son usage professionnel à grande échelle.
Mais ce n’est que le début. Cette architecture va rapidement essaimer vers tous les domaines du traitement automatique du langage, puis au-delà, vers la vision par ordinateur, l’analyse de graphes, la biologie computationnelle. Les Transformers deviennent l’architecture unificatrice de l’intelligence artificielle moderne, le substrat technique sur lequel se construisent tous les grands modèles contemporains.
Pourtant, une architecture révolutionnaire ne suffit pas. Car le secret le plus troublant de ces systèmes ne réside pas dans leur structure, mais dans ce qui va suivre : un processus d’apprentissage si mystérieux que même leurs créateurs peinent parfois à expliquer pourquoi il fonctionne si bien…
Les tokens, la réalité technique derrière la métaphore
Avant de plonger dans les mystères de l’entraînement, il est temps de révéler une simplification que j’ai volontairement maintenue jusqu’ici : les LLM ne prédisent pas vraiment des « mots » au sens traditionnel, mais des « tokens ». Cette distinction technique, loin d’être anecdotique, éclaire certains comportements mystérieux de ces systèmes et explique plusieurs de leurs caractéristiques pratiques.
Qu’est-ce qu’un token exactement ? Imaginez que vous deviez découper une phrase non pas en mots complets comme nous le faisons naturellement, mais en fragments plus subtils qui respectent la logique interne de la langue. Un token peut être un mot entier (« chat »), un fragment de mot (« man- » de « mange »), un suffixe (« -tion »), voire un simple caractère dans certaines langues. Cette fragmentation, réalisée par des algorithmes appelés « tokenizers », révèle une intelligence cachée : elle permet au système de généraliser sa compréhension linguistique.
Prenons un exemple concret. La phrase « Le chat mange une souris » pourrait être tokenisée ainsi : [« Le », « chat », « man », « ge », « une », « sou », « ris »]. Cette décomposition peut sembler artificielle, mais elle cache une logique profonde : en séparant « mange » en « man » + « ge », le système peut intuitivement comprendre « mangera », « mangeait », « mangeons » sans qu’on lui enseigne explicitement les règles de conjugaison française.
Pourquoi cette distinction change-t-elle tout ? D’abord, elle explique l’économie des LLM : quand vous utilisez l’API d’OpenAI, vous payez par token, pas par mot. « Bonjour » coûte un token, « anticonstitutionnellement » en coûte plusieurs. Cette asymétrie reflète la complexité computationnelle réelle du traitement.
Ensuite, elle éclaire les limites de contexte : les fameux « 128 000 tokens » de GPT-4 correspondent à environ 80 000-100 000 mots français selon la complexité du vocabulaire. Cette nuance est cruciale pour comprendre les vraies capacités de traitement textuel.
Enfin, elle révèle les biais linguistiques subtils : l’anglais, optimisé dans la plupart des systèmes, requiert généralement moins de tokens que le français pour exprimer la même idée. Cette asymétrie technique influence discrètement les performances multilingues des modèles.
L’art de la tokenisation explique aussi pourquoi les LLM manient si bien les néologismes et termes techniques : ils reconnaissent des fragments familiers dans des mots inconnus, reconstituant intuitivement le sens par assemblage morphologique. C’est cette granularité fine qui permet aux modèles de généraliser au-delà de leurs données d’entraînement avec une aisance qui nous surprend encore.
Cette révélation technique n’ôte rien à la magie de ces systèmes. Au contraire, elle révèle la sophistication cachée derrière l’apparente simplicité de la « prédiction de mots ». Token par token, ces machines recomposent la richesse du langage humain avec une précision qui confine à l’art.
Mais comment cette recomposition token par token devient-elle possible ? Comment des fragments de mots se transforment-ils en intelligence apparente ? C’est là qu’intervient le processus le plus fascinant de toute cette révolution technologique : l’entraînement des modèles de langage.
La suite vous emmènera là où tout commence vraiment : au cœur du processus d’apprentissage qui transforme des lignes de code en une intelligence troublante. C’est là que la machine, patiemment, apprend à parler… et à penser.